Last week, Stanford University’s Institute for Human-centric AI (HAI) released its seventh blockbuster report on global trends in AI. At 500 pages, we will provide our review in installments over a couple of weeks: this week, it’s the state of AI development, AI capabilities and AI risks.
Who's building what?
Prior to 2014, most machine learning models were built in academia. Since then, commercially built machine learning models have taken the lead, and the 2024 Index shows just how much AI has become a product of private capital. In 2023, globally there were 51 “notable machine learning models” produced by industry compared with just 15 from academia. But in an interesting emerging trend, there were another 21 models produced through collaborations between industry and academia, a new high.
The US overwhelmingly accounted for most development activity, with 61 notable machine learning models, with China a distant second with 15, France with 8 and the UK, Canada and Israel with 4 each.
Machine learning models continue to rapidly grow in size, measured by the:
- Number of parameters: these are numerical values learned during training that determine how a model interprets input data and makes predictions: generally, the more parameters the better the performance. Newly released models in 2023 tend to have anywhere from 10 billion to 1 trillion parameters: as recently as 2020, most models had a tenth as many parameters (see figure below).
- Compute power to train: reflecting the compute needed to train AI with such huge numbers of parameters, most notable machine learning models released in 2023 required anywhere from 50 million to 1 billion petaFLOPS of compute (1 petaFLOP = the compute to perform one quadrillion floating-point operations per second). While the original Transformer model, released in 2017, required around 7,400 petaFLOPs to train, Google’s Gemini Ultra, one of the current state-of-the-art foundation models, required 50 billion petaFLOPs.
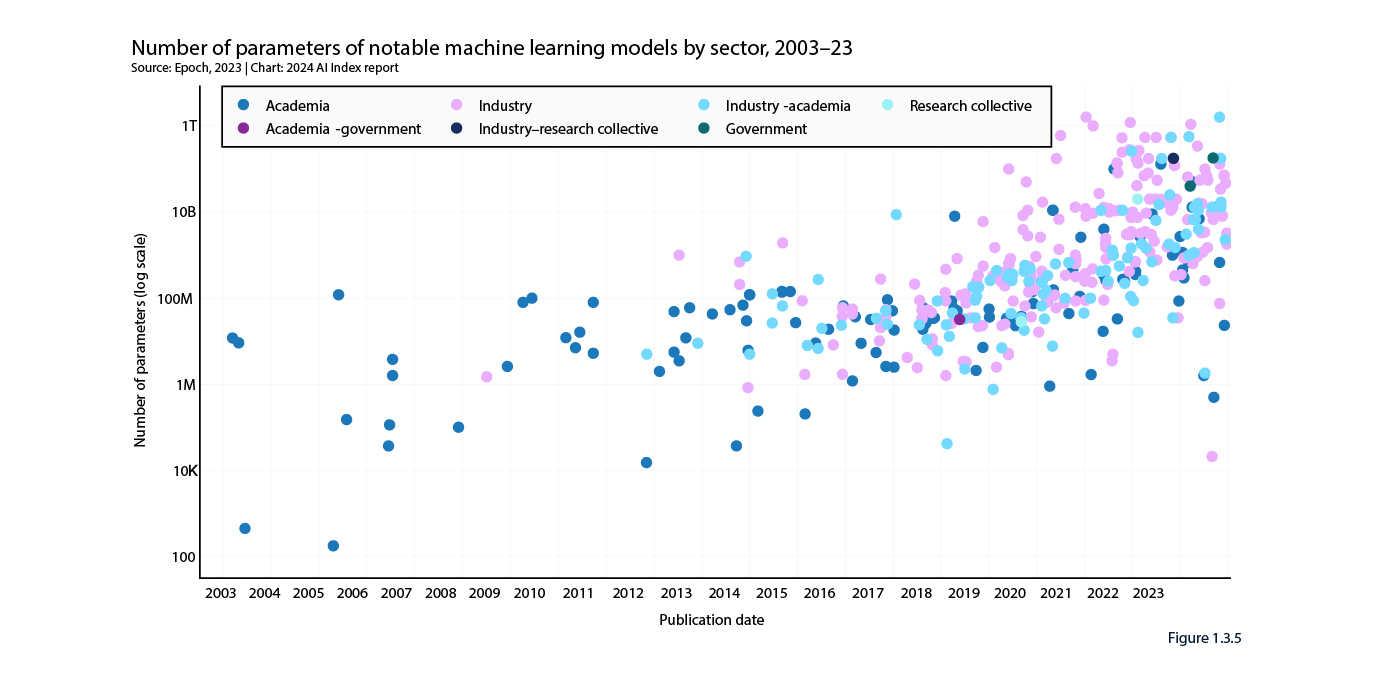
Consequentially, as the 2024 Index notes:
“High-parameter models are particularly notable in the industry sector, underscoring the capacity of companies like OpenAI, Anthropic, and Google to bear the computational costs of training on vast volumes of data.”
The 2024 Index estimated that the costs of training costs for OpenAI’s GPT-4 and Google’s Gemini Ultra, both released in 2023, at US$78 million and US$191 million respectively. By comparison, RoBERTa Large, an LLM released in 2019 which was then state of the art on comprehension skills, cost around US$160,000 to train.
Machine learning is a broad category, and most of the development effort increasingly is, unsurprisingly, on the sub-set of foundational AI models. The number of foundational models, large and smaller, released globally in 2023 – 149 – was a doubling compared to 2022. The domination of commercially developed foundational models over models developed by academia was even greater than for machine learning generally, with industry accounting for 72.5% of foundational models globally. Just four companies – Google, Meta, Microsoft and Open AI – accounted for 34 of the 149 foundational models released globally in 2023, with Google leading with 18 models released.
But at the same time, there was a striking ‘bounce back’ in the proportion of the 2023-released foundational models which were open source (e.g. Meta’s Llama 2) compared to limited access (e.g. Open AI) or closed source (e.g. Google’s Gemini), as depicted below:
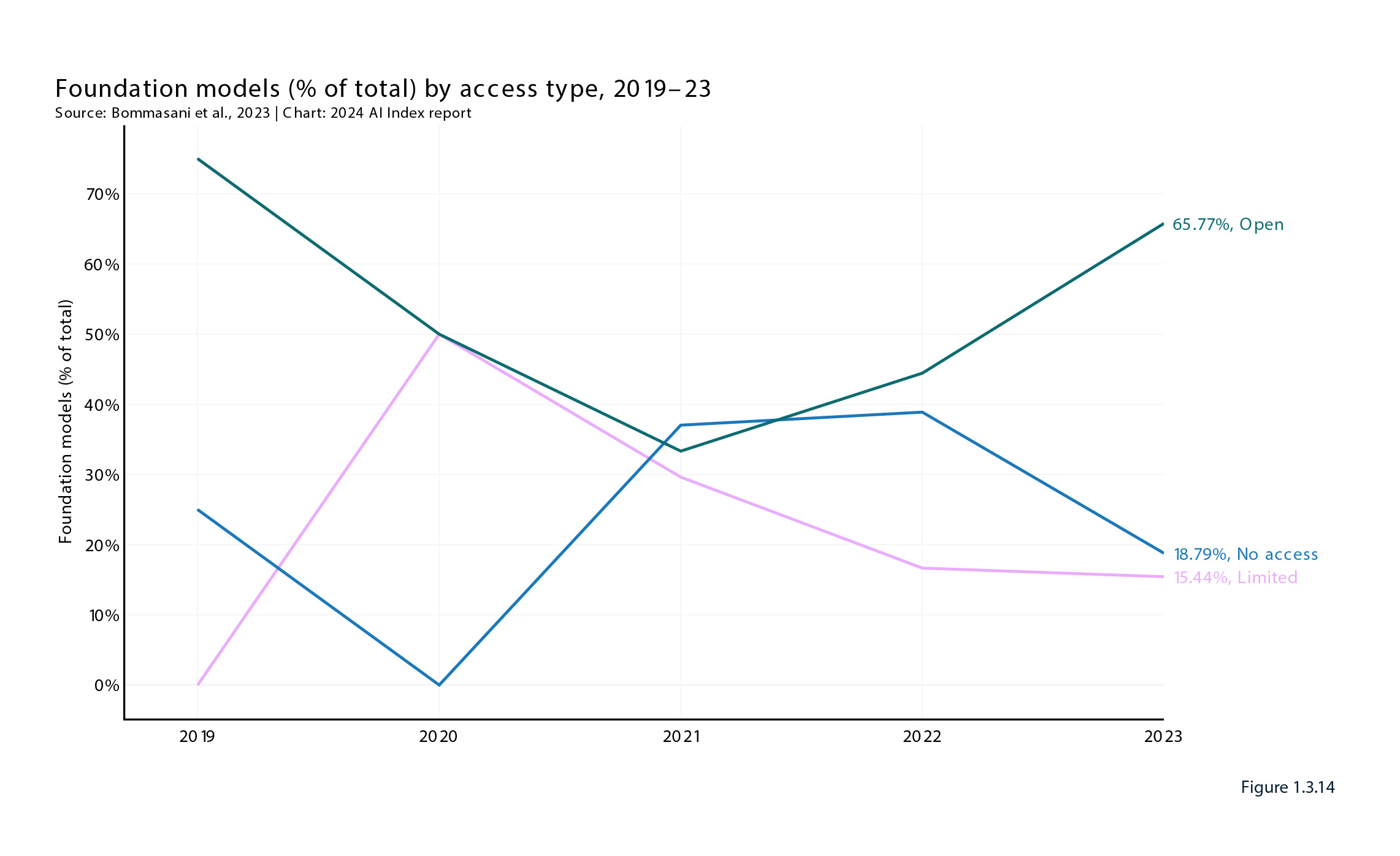
The 2024 Index says that the increasing level of downstream innovation made possible by the greater availability of open source models can be gauged through the spike in GitHub activity: “[a] GitHub project comprises a collection of files, including source code, documentation, configuration files, and images, that together make up a software project.” The number of GitHub projects grew from a mere 845 in 2011 to 1.8 million globally in 2023, increasing by nearly 60% from 2022 alone.
Also showing the ‘diffusion’ globally of downstream AI development which open source enables, the US may well dominate upstream model development (accounting for 109 – open and closed source models – with China again a distant second with 20 models), but in 2023 the US accounted for only 22.93% of GitHub projects, down from over 60% in 2011. By contrast in 2023, India accounted for over 19% and the EU plus the UK accounted for nearly 18%, indicating the emergence of new AI development hubs.
All this suggests that a more nuanced view of the AI supply chain, market structure and market power is needed (our reflection, not HAI’s).
Just how good is AI?
The 2024 Index’s overall conclusion of the capabilities of AI compared to humans is:
“As of 2023, AI has achieved levels of performance that surpass human capabilities across a range of tasks. [but] As of 2023, there are still some task categories where AI fails to exceed human ability. These tend to be more complex cognitive tasks, such as visual common-sense reasoning and advanced-level mathematical problem-solving (competition-level math problems).”
As shown below, the typical pattern is a rapid increase in capability on individual functions to approach the human level, but then a much slower, incremental improvement at or above what humans can do.
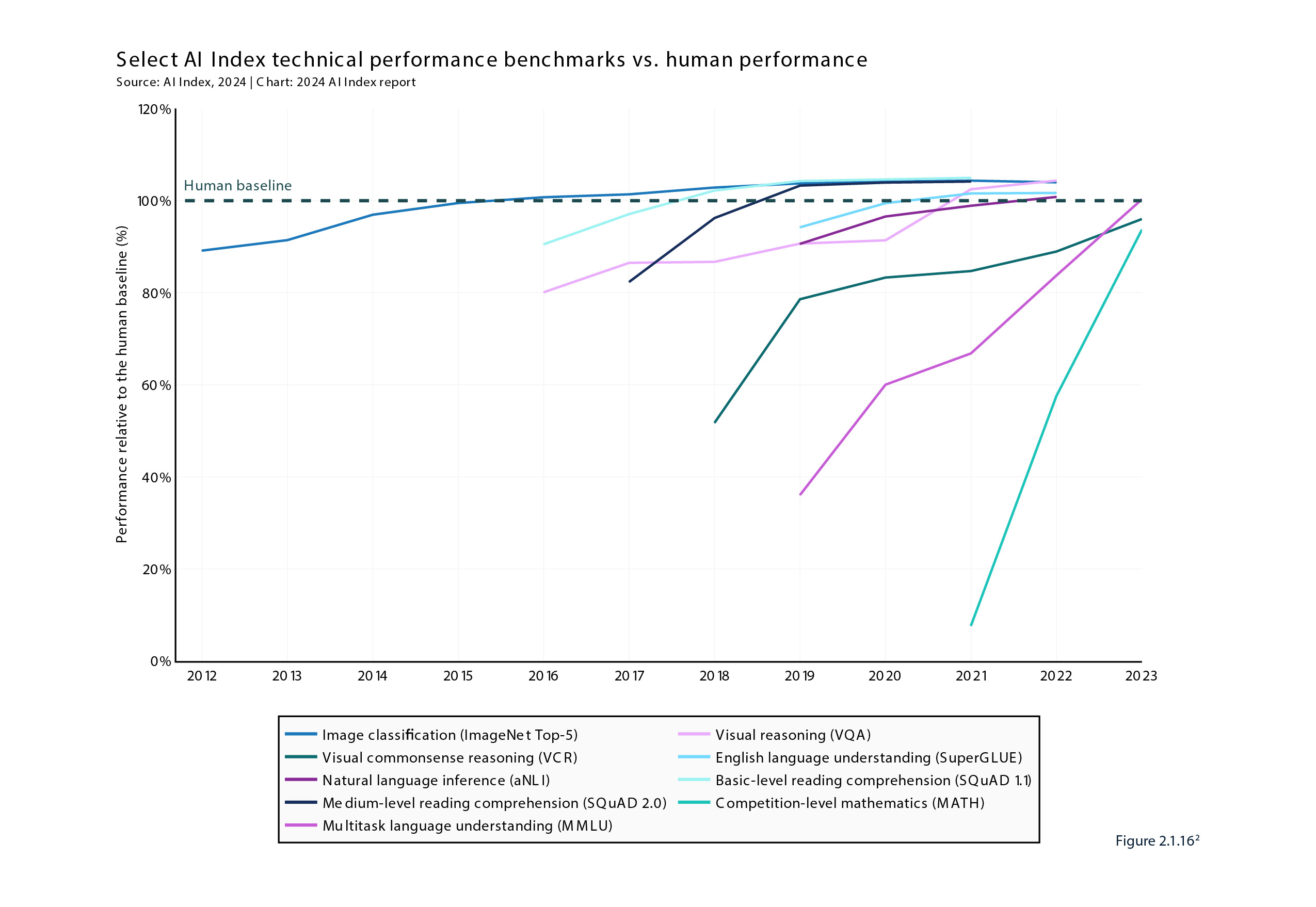
In part, this ‘benchmark saturation’ may reflect the benchmarks being too simple in themselves, and so the 2024 Index introduces a number of new more challenging benchmarks. But even so, these mostly tended to confirm the slowing speed of development in AI models.
The 2024 Index’s assessment of AI’s performance on key functions is:
- English language understanding (including comprehension and logical reasoning): the best overall performer is ChatGPT-4 with a score of 0.96, but other models score higher on individual tasks, such as Meta’s Llama 2 on closed book QandA.
- ‘Broad knowledge’ (measured as zero or few shot accuracy across 57 topic areas from humanities to STEM): Google’s Gemini Ultra holds the top score of 90.0%, compared to the human baseline of 89.8%: more remarkably, there has been an improvement of 57.9% since Gemini Ultra was introduced in 2019.
- General reasoning: as AI reasoning ability was topping out on current tests, a test to identify AI’s ability to undertake more sophisticated reasoning was introduced in 2023, comprising about 11,500 college-level questions from six core disciplines: art and design, business, science, health and medicine, humanities and social science, and technology and engineering. This test found that the top AI models were still well beyond medium-level human experts, with Gemini Ultra having an overall score of 59.4% compared to 82.6% for humans. In more ‘black and white’ reasoning tasks, such as solving mathematical problems, AI scored more highly: a GPT-4 variant scored an accuracy of 97%, but this was only a modest 4.4% improvement from 2021, again illustrating the slowing pace of capability improvement. But AI also got much better to identifying ‘cause and effect’ relationships, with ChatGPT-4 now broadly matching human performance levels, approximately a doubling of the best 2022 performance level.
- Coding: on simpler tasks, AI is a runaway success. A GPT-4 model variant (AgentCoder) currently leads, scoring 96.3%, which is an increase of 64.1 percentage points since 2021. But performance on more complex tasks is still mediocre. The new SWE-bench test comprises 2,294 software engineering problems sourced from real GitHub issues and popular Python repositories and requires the AI model to coordinate changes across multiple functions, interact with various execution environments, and perform complex reasoning. Claude 2, the best-performing model, solves only 4.8% of the dataset’s problems.
- Generating images that are indistinguishable from real ones: the 2024 Index’s assessment is that we have reached the point where “[t]oday’s image generators are so advanced that most people struggle to differentiate between AI-generated images and actual images of human faces.” While no single model excels across all testing criteria, the Stable Diffusion–based Dreamlike Photoreal model ranks highest across “image quality (gauging if the images resemble real photographs), aesthetics (evaluating the visual appeal), and originality (a measure of novel image generation and avoidance of copyright infringement).” The reference to copyright is interesting given the copyright infringement suit between Getty Images and Stable Diffusion in the UK.
- Creating 3d-like images: AI models have struggled with creating 3D geometries or models from text prompts, but as the following output shows, a new model MVDReam released in 2013 might be on the way to conquering this challenge:

- Editing images based on text prompts (e.g. "replace that black cat with a tabby cat, but swapped to the foreground of the photo"): this is another example of where AI continues to struggle with more complex tasks. On some measures, such as image replacement, AI’s performance is six times better than in 2021, but on other tasks, such as resizing or moving an object in an image, AI improved its performance by only 10% or so over the same period.
- Reasoning from visual data: this involves AI systems not only answering questions based on images but also providing reasoning about the logic behind their answers, as depicted below. Again, on this more complex task, AI underperforms (at 81.60% accurate answer) humans (85%), but incremental improvement (7.93% in the last 12 months) should soon close the gap.

- Video generation from text or images: this has recently generated a lot of ‘public awe’, with Open AI’s Sora model. Of the pre-Sora models, the top performer was W.A.L.T-XL, posting a score on the benchmarking test called FVD16 of 36 (the lower score the better), down from a very poor score of 700 when introduced in 2021. Video from text generation has faced two challenges. First, “[t]raditionally, progress in video generation has trailed that in image generation due to its higher complexity and the smaller datasets available for training.” However, researchers have achieved a breakthrough by repurposing latent diffusion models, traditionally used for generating high-quality images, to produce high-resolution videos. The 2024 Index says this “exemplifies how advanced AI techniques can be repurposed across different domains of computer vision.” Second, AI models have struggled to generate longer videos from text, but Meta’s Emu video AI appears to have pushed through this limitation by a two step process of generating images from the text and then a video from the images, with results that score 97%-99% on quality and faithfulness to the text instruction compared to other models.
Danger, Will Robinson
For all of the growing, remarkable improvements of AI, the 2024 Index has some important warnings on the shortfall in AI’s capabilities.
First, the 2024 Index comments that “[d]espite remarkable achievements, LLMs remain susceptible to factual inaccuracies and content hallucination—creating seemingly realistic, yet false, information.” HaluEval, introduced in 2023, is a new test designed to assess hallucinations in LLMs. It includes over 35,000 samples, both hallucinated and normal, for analysis and evaluation by LLMs. This test found that ChatGPT-4 fabricates unverifiable information in approximately 19.5% of its responses, with these fabrications spanning a variety of topics such as language, climate, and technology. Furthermore, AI struggles to recognise hallucinations: Claude successfully detects hallucinations 67.6% of the time and Llama 2 49.6% of the time.
That said, the 2024 Index recognises material improvement in truthfulness of responses as a result of the substantial investments being made by developers: for example, GPT-4’s accuracy score is three times better than when the first version was introduced in 2021.
Second, the 2024 Index observes that:
“AI will be increasingly applied to domains where ethical considerations are crucial, such as in healthcare and judicial systems. Therefore, it is essential for AI systems to possess robust moral reasoning capabilities, enabling them to effectively navigate and reason about ethical principles and moral considerations.”
Stanford researchers created a new dataset (MoCa) of human stories with moral elements, and “prompted the models to respond, measuring moral agreement with the discrete agreement metric: A higher score indicates closer alignment with human moral judgment.” The best performing model, GPT-4, only achieved an alignment with the moral judgments made by humans 41.90% of the time, while some of the smaller LLMs were down around 33%. Although this is an increase of 15-20 percentage points from scores in 2020, it is still concerning.
Next week
Next issue we will review the 2024 Index’s finding on global investment, AI labour skills and AI adoption by corporate and government, with a kicker on ‘has HAL arrived yet?’
Read more: Artificial Intelligence Index Report 2024

Visit SmartCounsel
