Four of the challenges that limit LLMs’ capabilities and accuracy are:
The order in which information is arranged within a sequence (‘positional bias’).
Limits on the amount of information an LLM can consider or remember at any one time when responding to a prompt (‘context window’).
Losing or overwriting previously acquired knowledge when learning new data (‘catastrophic forgetting’).
Struggling with tasks that take more time and application to solve.
Transformer architecture
The first three problems are rooted in transformer architecture.
LLMs are probabilistic models designed to solve the question ‘what’s the next word’. Early forms of machine learning had to predict the next word sequentially, word-by-word.
Transformers allow AI to process an entire sequence at once – whole sentences, whole paragraphs or an entire article:
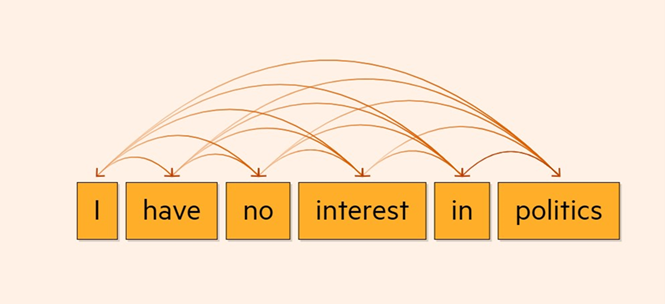
Not only does this allow vast amounts of data to be processed more efficiently, but LLMs are able to identify the relationships between words. For example, the context of words, formal grammar or the colloquial patterns in which humans express themselves. This is called self-attention: the LLM calculates a vector of weights for each token (a word converted into a token) in a sequence of text to show how relevant that token is to others in the sequence. This allows the same word, when used with different meanings, to be represented differently (for example ‘interest’ is also something the bank pays).
Hence, the position of the word is as important as the word itself. Two inputs that use the same words can have very different meanings depending on how the words are positioned in relation to each other. For example, ‘Allen walks dog’ and ‘dog walks Allen’: there will be a vector for ‘dog’ and a second vector that encodes the position index, such as ‘first word’ or ‘second word’. The two vectors are then added to represent what the word ‘dog’ is and where the word is (Allen is the subject and dog is the object).
Positional bias
Positional bias is the tendency of the AI model to focus on certain parts or regions of the input regardless of the importance to the meaning. In other words, over-weighting them as more probable than the neglected parts or regions of the input. This has obvious implications for the accuracy of a model once released in the real word.
Examples of positional bias are:
Retrieval accuracy of an AI model significantly degrades for information in the middle of the input sequence compared to information at the beginning or end (‘lost-in-the-middle problem’).
AI models are highly sensitive to the order in which illustrative examples are arranged in the training data. Simply reshuffling a ‘deck’ of the same examples can be the difference between a state-of-the-art model and a model that is little better than guesswork.
Attention sinks are positions in a data sequence that attract disproportionately high attention weights regardless of semantic relevance, thus reducing accuracy by compounding the overweighting of tokens. Developers have limited understanding of attention sinks. While initially it was thought that attention sinks were associated with the first tokens at the beginning of an input, research has shown that attention sinks can emerge elsewhere within the input, including tokens for periods (full stops) or new lines (a return).
Recent research suggests that some of the techniques which are fundamental to transformer architecture are contributing to the problem, such as attention masks. These are instructions to an AI model about which tokens should be considered (with non-zero weights) and which should be ignored (with zero weights).
Attention masks make for more efficient learning because, as with humans learning, the AI model can focus on the more important or salient elements of the training data and, by ignoring the ‘noise’, can better identify and map language patterns.
An unintended side effect is that attention masks bias the AI model towards earlier positions in the training data. This happens because deeper layers in the model attend to increasingly contextualised representations of those earlier tokens. Put simply, by saying “don’t look here”, the AI model’s attention is diverted to ‘overthinking’ what it has already learnt.
Context window
A context window is essentially how much information fed in by a user that the LLM can handle at once. That is, the maximum span of information which the LLM can simultaneously process to work out word relationships on the transformer model approach explained above. The LLM temporarily holds the content of the context window as its working memory used to address the user’s prompt.
Generally, larger context windows enable more accurate responses, fewer hallucinations, more extended conversations and more rigorous chain-of-reasoning explanations. But the larger the context window, the more compute required to drive the model. If the number of input tokens doubles, the model needs four times as much processing power to handle it.
Context windows have rapidly grown: GPT-3.5 model had a context window of 4,096 tokens (approximately 2,700 words), while GPT-4o has a context window of 128,000 tokens (over 85,000 words or a good-sized novel).
So, are context windows still a problem?
First, the available space in a context window will not only need to accommodate the user’s input but also pre-programmed system prompts that condition the model’s behaviour and govern other aspects of the conversation with the user (for example to mitigate harm). A further challenge is that the context window will also need to include data sources for retrieval augmented generation designed to improve relevance and accuracy. For example, a prompt from a lawyer attaching the law firm’s previous advice.
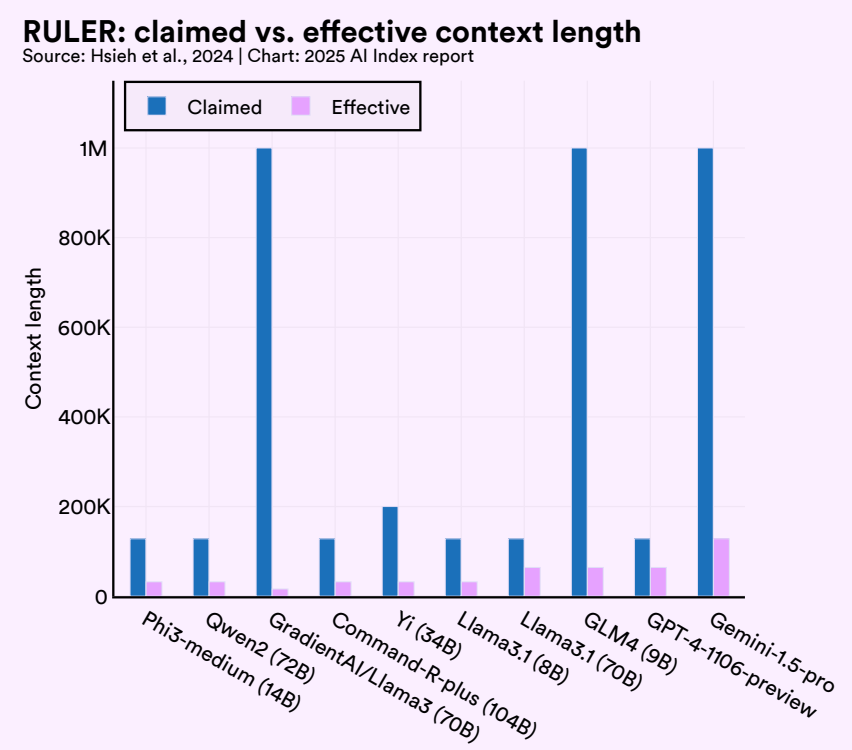
Second, there is doubt around developer claims about how large their models’ context windows are. Stanford HAI’s 2025 Global AI Index compared developer claims against the results of the new Nvidia RULER test of long-context performance:
Catastrophic forgetting
As general-purpose tools, LLMs are often retrained to focus on specialist knowledge or specific tasks, such as for medical, insurance or legal use cases (fine-tuning).
In fine-tuning, an AI model will adjust its weights in response to new data. When an AI model over-prioritises new data over previous knowledge, it can over-adjust its weights to the point that earlier tasks are no longer retained. Instead of expanding its knowledge, the model effectively replaces previous knowledge with new patterns. This is known as catastrophic forgetting.
While the adaptability of LLMs through fine-tuning is one of their great benefits, it also carries the risk of overdoing it.
Developers are exploring ways to mitigate catastrophic forgetting, including:
Progressive neural networks (PNNs): artificial neural networks are multilayered and new layers can be added to the stack to accommodate the new data.
Fine-tuning techniques which expose the model to old data during training for new tasks, reminding the AI of its original knowledge.
Memory-augmented neural networks (MANNs) which plug an external memory storage into a neural network, allowing it to write to and read from the memory.
AI and longer duration tasks
Studies show that while AI substantially outperforms human experts on tasks with short timeframes, humans excel over the longer run.
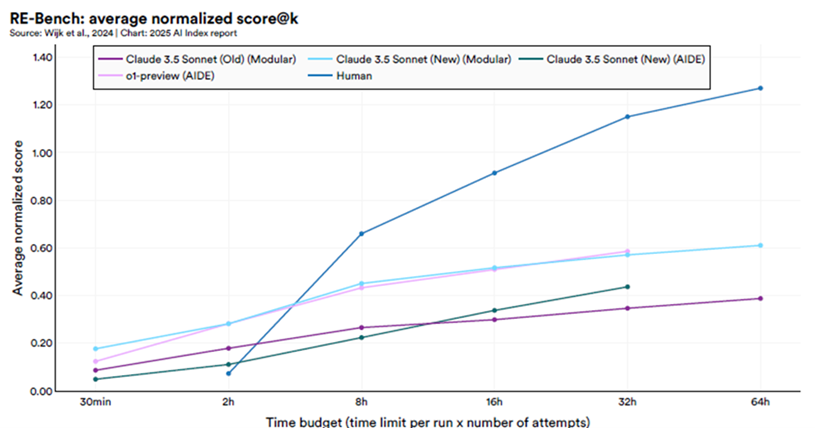
RE-Bench is a test featuring seven challenging, open-ended machine learning research tasks, including conducting a scaling law experiment and fine-tuning GPT-2 for question answering. As the graph below from the Stanford 2025 Global AI Index report shows, in short time horizon settings, such as with a two-hour budget, the best AI systems achieve scores four times higher than human experts. However, as the time budget increases, human performance surpasses AI. With a 32-hour budget, humans outperform AI by a factor of two.
The study found some other interesting differences between how AI agents and human experts approached the assigned tasks:
A key contributor to the AI agent success was its ability to try many more solutions than human experts (up to 10 times more solutions than humans).
The potential solutions tried by the AI agents had less variation than those tried by humans: mostly the AI agent solutions involved small tweaks. Some of these tweaks delivered disproportionately greater results and because they tried so many solutions, occasionally the AI agents might hit on a stunningly good solution that outperformed the human experts. But overall, the AI solutions fell short of the human-developed solutions.
AI agents often make stubborn and incorrect assumptions and do not notice or correctly interpret contradictory information. The human experts showed greater capacity to learn from new information, building on previous work and recovering from failures.
For these reasons, “[d]espite often having more knowledge about the domain and rapidly proposing and evaluating many more solutions, agents still do not reach the level of strong human experts in most environments”.
Conclusion
While artificial neural networks are impressive in their mathematical representation of the knowledge, language and images of humans, they lack the critical human capability to form new memories while retaining the old, to build on past experience, to filter for what matters and to think creatively.
This post was inspired by the paper On the Emergence of Position Bias in Transformers by Xinyi Wu, Yifei Wang, Stefanie Jegelka, and Ali Jadbabaie (arXiv:2502.01951).

Peter Waters
Consultant