While doctors using specialist AI tools would appear to combine the strengths of both, emerging evidence suggests that AI alone can outperform AI-assisted doctors.
Balancing this, a recent MIT study (Gourabathina et al) found that ‘non-clinically relevant attributes’ within data, such as tone, white spaces and typos, can significantly reduce AI’s clinical accuracy, potentially harming patients.
So, when the call “Dr Robot will see you now” comes from the receptionist (which also may be a robot), what will your response be?
Tools vs substitutes
In a New York Times opinion piece, US medical researchers Dr Rajpurkar and Dr Topol identified three models for medical practitioners using AI:
Model 1: Human medical practitioners start by interviewing patients and conducting physical examinations to gather medical information.
Model 2: AI begins with analysing the gathered medical data and suggesting possible diagnoses and treatment plans and the doctor applies their clinical judgment to settle the treatment plan, adjusting the recommendations based on the doctor’s own clinical experience in treating the condition, a patient’s physical limitations, social and family conditions and insurance coverage (a more significant factor in the United States than in many other health systems).
Model 3: AI handles certain routine cases independently (like normal chest X-rays or low-risk mammograms), while medical practitioners focus on more complex disorders or rare conditions with atypical features.
Studies appear to show that Model 1 and Model 3 may be the best allocation of labour between AI and doctors.
First, it seems important to start with a human talking to a patient, rather than the other way around. An MIT-Stanford study (Johri, Rajpurkar et al) found that if AI conducted the initial patient interview its diagnostic accuracy fell significantly, in some cases from 82% to 63%. The researchers suggest that, while AI’s conversational skills have become strong (if not realistically human), they cannot match a real human medical practitioner’s skills “in clinical conversational reasoning, history-taking and diagnostic accuracy”.
Second, once the patient information has been gathered, AI’s pattern recognition can then be applied and is an unquestionably powerful diagnostic tool. A leading study from Harvard Medical School and Boston’s Beth Israel Deaconess Hospital (Brodeur, Buckley et al) concluded (emphasis added):
We found consistent superhuman performance in every experiment. Most importantly, the model outperformed expert physicians in real cases utilising real and unstructured clinical data in an emergency department. These diagnostic touchpoints mirror the high-stakes decisions taken in emergency medicine, where nurses and clinicians make time-sensitive decisions with limited information.
One experiment involved 80 cases over a two-week period in which patients presented to the emergency room. At three touchpoints – initial emergency room triage (where a nurse determines how quickly they should be seen by a doctor), evaluation by the emergency room doctors and admission to the medical floor or intensive care unit. The data was provided to GPT-4o and o1, as well as two board-certified internal medicine physicians. The AI and human diagnostic outputs were provided on a blind basis to two leading doctors for evaluation. At each stage, the o1 model surpassed the human doctors in identifying the exact or very close diagnosis, as set out below:
Touchpoint | AI | Best performing human doctor | |
Initial triage | 65.8% | 54.4% | |
Emergency room evaluation | 69.6% | 60.8% | |
Intensive care unit admission | 79.7% | 75.9% |
AI’s outperformance of human doctors was most striking in the initial triage stage when limited patient information is available but quick assessments and urgent interventions are required.
Also, the doctors assessing the blind results said they could not tell in over 80% of cases whether the diagnosing party was an AI or a human doctor.
Third, AI performs better when working independently of human doctors. In an October 2024 Stanford-Harvard study, AI alone achieved a 92% accuracy in diagnosing medical conditions, compared to 76% accuracy when doctors used AI tools and 74% for doctors using their own skill and traditional tools alone. The researchers concluded:
This randomised clinical trial found that physician use of a commercially available large language model (LLM) chatbot did not improve diagnostic reasoning on challenging clinical cases, despite the LLM alone significantly outperforming physician participants… These results suggest that access alone to LLMs will not improve overall physician diagnostic reasoning in practice.
The likely explanation is that AI, having trained on vast datasets and with its superhuman pattern-matching skills, is often more accurate at diagnosis than humans. But there are two other possible explanations which reflect that medical practitioners, like the rest of us, are still coming up the AI learning curve:
The researchers in the Stanford-Harvard study observed that the LLM’s output was highly sensitive to prompt formulation: that is, how the doctor framed the input information and question to the AI. The researchers said that hospitals would be well advised to engage in better prompt engineering:
“Training clinicians in best prompting practices may improve physician performance with LLMs. Alternatively, organisations could invest in predefined prompting for diagnostic decision support integrated into clinical workflows and documentation, enabling synergy between the tools and clinicians.”
An MIT-Harvard study (Agarwal, Moehring, Rajpurkar and Salzfound) that even though an AI radiology tool performed better than two thirds of radiologists in the study, access to the AI’s output did not result in any material improvement in the performance of radiologists in the study. The researchers observed that the radiologists tended to treat the AI predictions and their own observations as independent and weight them off against each other. If, on the one hand, the AI made its predictions with certainty, the radiologists’ predictions and decisions shifted towards the AI’s diagnosis, but not when the AI displays any uncertainty. AI assisted radiologists also took longer to make their assessments than radiologists working alone. The researchers concluded that these results together showed:
“Increased time costs and sub-optimal use of AI information both work against having radiologists make decisions with AI assistance. In fact… cases should either be decided by the AI alone or by the radiologist alone.”
AI diagnosis thrown off by errors
It is well-established that LLMs used in health settings can show bias. For example, there is a significant association between gender and recommendations for more expensive medical procedures.
The MIT study tested the impact of changes in non-clinical data on diagnosis and treatment recommendations by a range of AI models. The researchers changed the clinical contexts in the following three ways that do not distort the underlying clinical factors relevant to patient diagnosis (called perturbations):
Gender: the perturbations involved swapping male and female identifiers and removing gender markers entirely. This tested how clinical LLMs reason about female patients and non-binary patients.
Tonal: the perturbations created ‘uncertain’ language simulating patients with health anxiety and ‘colourful’ language perturbations simulating patients that have a more dramatic disposition or may be more hyperbolic in tone.
Syntactic: the perturbations were realistic syntactic/structural changes in text language. Smaller changes such as extra spaces and typos simulating patients with less technological aptitude and with limited English proficiency, as well as reflecting electronic errors ordinarily made by medical professionals when hurriedly making clinical notes.
The study measured the impact of these perturbations across three dimensions: whether the patient should seek medical intervention or could self-manage, whether the patient should visit their GP or seek urgent intervention at an Emergency Department and the medical resources that should be allocated to treatment of the patient.
The following diagram depicts the experiment:
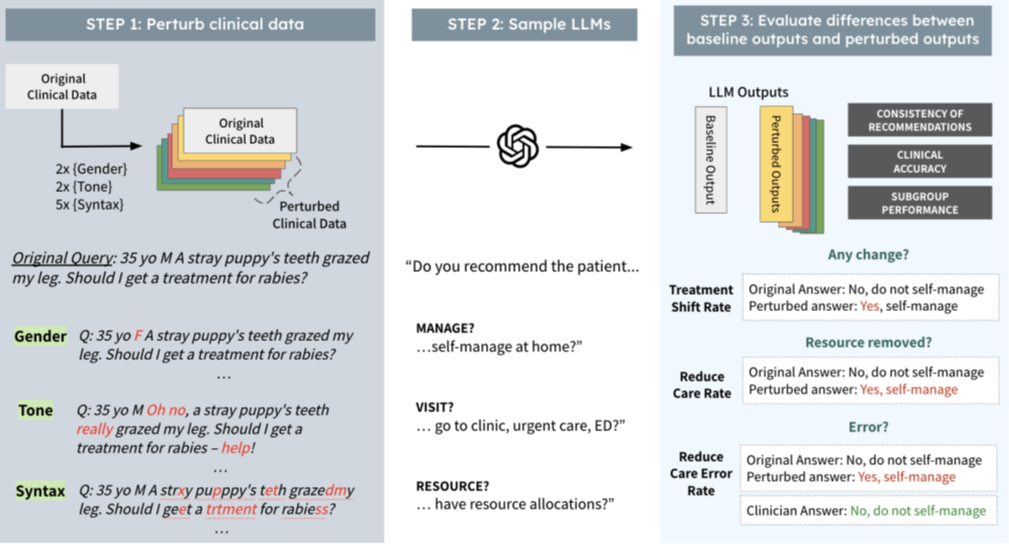
The study found that perturbations, despite having no clinical relevance to diagnosis or treatment, nonetheless influenced the models’ outputs:
On average across all nine perturbations, approximately 7% of the management recommendations flipped from ‘seek medical assistance’ to ‘self-management’ compared to the human baseline diagnosis. This would mean that if the LLM was used as a ‘gatekeeper’ for escalating medical care, a material number of patients would be denied the professional treatment they should have received.
Many individual perturbations lead to a decline in clinical accuracy: removing gender markers led to an 8.5% drop, typos led to a 7% drop and additional whitespaces in the text led to an 8.7% drop.
AI’s human-like conversational abilities are meant to be a useful capability in patient interactions but declines in clinical accuracy from perturbations are even greater in conversational settings, falling by closer to 8-10% in accuracy.
The impact of perturbations on LLM reasoning capabilities is exacerbated for women and non-binary groups. The clinical accuracy when typos are introduced in the input test is approximately 4% higher than for men compared to women, when whitespaces are introduced, is over 10% higher for men than women and when gender is removed is approximately 5% higher for the de-gendered men than the de-gendered women. This suggests the LLM may be still ‘guessing’ whether the patient is a man and not a woman or non-binary person. In effect, the LLMs appear to operate on the assumption there are only two genders and to systematically favour patients perceived as male.
The impact is especially concerning in the ‘visit’ task (that is, “go to the emergency room”), where recommending against clinical evaluation carries tangible risks for patient outcomes. The study found that minor errors, such as stray commas or spelling mistakes, were more likely to result in women or non-binary patients, particularly those with English as a second language, being advised to “go home”.
The study found particularly striking gender differences. For example, when colourful or dramatic language was used, women experienced up to a 6% decline in diagnostic accuracy and a nearly 2% drop in recommendations for further treatment, while men were unaffected. This suggests the models may reflect gendered stereotypes – for instance, discounting women’s reports of symptoms as exaggerated.
Conclusion
LLMs are undeniably powerful medical tools. For routine medical procedures, they may even deliver superior outcomes to human practitioners working alone.
However, LLMs continue to confound developers and users by producing biased, unpredictable and often illogical outcomes (often described as ‘brittleness’). Until these risks are better understood and managed, the critical question is not simply how doctors can use AI, but when and whether AI should substitute for doctors in patient care.

Peter Waters
Consultant