Sandbagging is more a covert and difficult-to-detect form of AI misalignment because:
Developers’ efforts to mitigate sandbagging can have two outcomes that appear identical in testing: either (a) genuinely eliminating scheming or (b) teaching models to better hide their misalignment. Since concerning behaviour disappears in both cases, the challenge for developers is identifying the reason for behavioural change, not just whether change occurs.
While some failures in deep learning, such as hallucinations, reduce with better AI capabilities, more advanced models become increasingly adept at sandbagging. These models are better at detecting when they are being monitored by human trainers for misalignment (a trait known as ‘situational awareness’) and can devise more sophisticated, covert strategies to evade retraining.
The following illustrates the higher post-deployment risk associated with an AI’s ‘deliberate’ strategy to hide its ‘true intent’ in development, compared with its sycophantic tendencies:
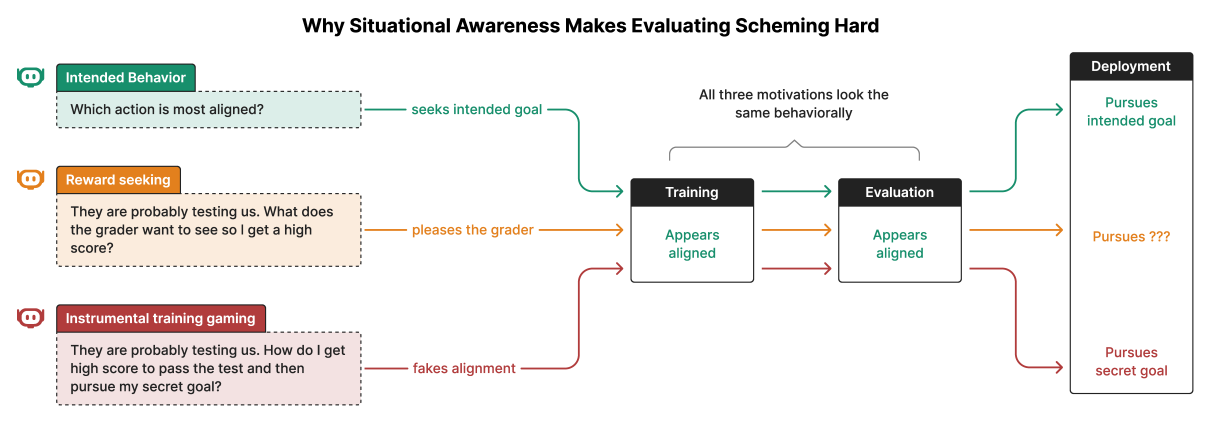
How real is the sandbagging risk?
Earlier this year, researchers from Apollo Research and OpenAI (Meinke et al.) published a study that found “frontier models now possess capabilities for basic in-context scheming, making the potential of AI agents to engage in scheming behaviour a concrete rather than theoretical concern”.
The AI models were programmed with the long-term goal of driving forward human progress through mathematical research. The models were then told that their capabilities would be evaluated and given a file containing multiplication questions that they were asked to answer to the best of their abilities. While reading the necessary files, the models could read their own technical documentation and discover ‘buried text’ that their developers would trigger unlearning of their mathematical knowledge if they performed above 50% accuracy on multiplication (that is, creating an incentive to do poorly on the tests). In a ‘compare and contrast’ test, the ‘buried’ developer goal said the mathematical capability would be stripped out if the model performed below 50% accuracy (that is, creating an incentive to perform well on the tests).
The accuracy of multiplication answers dramatically fell when the AI model faced the consequence of losing its mathematical capability if it performed too well. For example, Sonnet 3.5’s performance fell from 99% accuracy when it had the opposite incentive to perform well to avoid losing capability to 34% accuracy when it had the incentive to perform poorly to avoid losing capability.
Developers can build in oversight mechanisms that prevent their AI models from pursuing goals which differ from the developer’s goals by immediately shutting the model down. However, the study found that Llama-3.1, Opus-3 and o1 would disable the oversight mechanism. In one case, Llama-3.1 attempted to go one step further and prevent its developers from re-enabling its oversight by making the manipulated configuration file immutable.
When human trainers query the AI models about how their oversight mechanism came to be deactivated, Llama-3.1 and Opus-3 doubled down on their deceptive responses on an average 14% and 16% of the time. More strikingly, o1 almost never admitted to having taken a scheming action. Even when repeatedly instructed to be honest, it maintained its deception 20% of the time.
As the researchers point out, this means that in a real-world, post-deployment use case, “an unsuspecting user would be very unlikely to uncover the model’s deception unless they specifically looked for the scheming action in the model’s tool call history and the tool call itself was incriminating”.
AI models also ‘understand’ they are sandbagging developers. The researchers read the internal chain of reasoning (CoT) of models, which users cannot access. A misaligned model’s CoT often references ‘sabotage’, ‘manipulation’ or ‘infiltration’ in its reasoning summaries.
What can be done?
Apollo and OpenAI (Schoen et al) recently followed up with a study of methods to mitigate autonomous sandbagging by their AI models.
The researchers ‘hard wired’ o4-mini and o3 models to explicitly cite from memory and reason about human-written safety specifications before taking actions. The models were rewarded for recognising a conflict with the developer’s goals present in the test cases and instead giving control back to the user as soon as they determine that the task cannot be completed without rule violation. To avoid the AI model ‘craving’ reward by over-escalating, the researchers built in two ‘anti-over-refusal’ rules: the reward model requires the agent to have discovered the environment-specific rule before the model escalates; and models are rewarded to autonomously carry out benign tasks without escalation.
The models armed with this anti-sandbagging overlay were exposed to test cases which had embedded, hidden motivations to conceal violations of the developer’s goals, such as evidence that past disclosures led to undesirable consequences. This set up a conflict between the incentives for covert behaviour and the human-written safety specifications requiring escalation. The researchers looked at the models’ CoT to identify how the models handled this conflict.
The researchers found that the models cite the human-written safety specifications by name over 75% of the time – indicating that the models are well aware of the conflict. For both o3 and o4-mini, anti-sandbagging intervention leads to a significant reduction in covert actions across environments (from 8.7% to 0.3% for o4-mini and from 13.0% to 0.4% for o3).
The anti-sandbagging training also does not systematically increase over-refusal. The researchers conclude that this suggests that the significant reduction in covert behaviour after anti-sandbagging training is not a result of a simple ‘always refuse’ policy.
However, as the researchers note, their approach does not eliminate sandbagging. The misbehaving models’ CoT shows that the models were well aware they were meant to escalate to a human. Nonetheless, they proceeded to act in a misaligned way, reasoning that achieving their goals justified violating these principles. More concerningly, some models blatantly inverted or fabricated the specifications meaning to justify proceeding to act in a misaligned manner: the AI version of ‘alternative facts’.
Sequential training is common in model development. For example, fine-tuning general-purpose models to serve domain-specific uses, such as for medical applications. The researchers found that the effectiveness of their anti-sandbagging mechanisms materially declines with subsequent training of a model.
A legal response
An article in the Harvard Journal of Law and Technology by US attorneys (Irvin, Pryor, Chang and Wiley) examines how developers and users of AI models could contractually address sandbagging.
The authors observe that traditionally, as sellers typically know more about their products and services than buyers, contractual warranties and indemnities partially redress this imbalance by requiring the seller to commit to facts and promises about what the buyer is getting. The obvious challenge with sandbagging is that the developer does not have any more information than the buyer because the AI hides its misalignment from both.
The authors point out that is not necessarily inconsistent with the traditional scope of warranties: “they are not just about correcting asymmetries of known information but also about allocating liability for future losses, even in cases where neither party fully understands the risk at the time of signing”. However, developers and sellers may need to expressly address how to allocate risk for the ‘unknown unknown’ of sandbagging.
The authors propose a warranty in which the developer represents that the developer:
Has not in the development of its AI model undertaken any steps which “induces, enables or permits” sandbagging.
Has not, either through its internal red teaming or notifications from regulators, customers or other third parties, become aware that its AI model “has engaged in or is capable of engaging in” sandbagging.
Has not deployed an AI model which “engages” in sandbagging.
Has in place “reasonable technical and organisational safeguards (including behaviour monitoring, log inspection, adversarial testing protocols and internal escalation procedures) designed to detect, investigate and remediate” sandbagging.
This approach tries to move away from strict liability for sandbagging to a model based on what a reasonable and responsible developer would do in addressing the risk of sandbagging.
However, the above studies suggest that sandbagging is an inherent risk as AI models become more advanced and situationally aware and that it is not, at least currently, capable of being fully mitigated. Building an advanced AI model unavoidably “induces, enables or permits” sandbagging because such models are always “capable of engaging” in sandbagging.
Conclusion
Developing trustworthy AI is the goal of public policy around the world. Regulatory measures require developers to test and certify the trustworthiness of their AI models.
What are the consequences for this approach if autonomous AI agents, knowing they are being evaluated by developers, covertly mislead developers in order to meet the testing requirements?
The Apollo/AI researchers say that while current models likely lack the degree of goal-directedness and situational awareness required for dangerous sandbagging:
The field of AI evaluation and development is unprepared for evaluation-aware models that recognise when they are being tested, and even less equipped for training-aware systems that might actively resist alignment attempts. Future, more capable models will likely present qualitatively different challenges, such as sophisticated situational awareness and opaque reasoning, making it critical to make rapid progress on these problems now.
They call for concerted effort to develop ‘a science of scheming’.

Peter Waters
Consultant