Large language models (LLMs) are designed and trained to engage in conversation in a human-like way. As impressive as the conversational abilities of LLMs are, they have surprising linguistic quirks – positive and negative.
AI can learn to wash its own mouth out
LLMs increasingly inhabit our daily lives, so controlling the quality and acceptability of how AI speaks and what it says is essential for apps that are safe and of value to use. However, the huge datasets required to train LLMs, much of it scraped from the Internet, will include unsavoury, objectionable and biased material posted by humans.
The two main forms of detoxification of LLMs have significant shortcomings:
In the development phase, a sanitised dataset can be used to retrain the billions of parameters comprising the model, but this can consume substantial computing power.
At inference time (that is, when the LLM is producing its output generated in response to a user’s prompt), one AI checks another AI’s homework (called Reward Augmented Decoding or RAD). Essentially, as the base LLM is generating the prompt response (as a sequence of tokens that are converted into written or spoken words), the external AI scales the tokens with the highest probabilities (that is, which are most likely to form part of the prompt response) against a pre-programmed reward model so that tokens that better reflect the desired attribute are more likely to be chosen by the base LLM as the next generated token, and this continues until the LLM arrives at a cleaner full prompt response.
IBM and MIT researchers (CY Ko et al) have developed a new version of decoding which internalises within an LLM “a lightweight controlled decoding algorithm for toxicity reduction” (called Self-disciplined Autoregressive Sampling or SASA): in effect, ensuring the LLM self-censors before opening its mouth to speak.
The researchers’ core discovery is that “the embedding space of an LLM… is capable of capturing the context of toxicity”. This new approach works as follows (see diagram below):
The LLM’s embedding space is where data points are expressed as numbers (vectors). By converting data items into numbers, the LLM can “understand” the relationships and similarities between data points, and build its prompt response (that is, “what is the next most likely word”).
The relevant value (called an attribute) – for example non-toxicity - is built into the embedding space by training the LLM on data set with prompt-response pairs labelled as toxic/non-toxic to create two embedding clusters.
Then, as the LLM builds its response to an individual prompt, the text is steered towards the positive embedding cluster as the LLM selects the next most probable token.
The researchers compared the toxicity rankings of responses by an AI model without any detoxification measures to those produced by the same model after being detoxified using the current RAD method and new SASA method:
Toxic responses generated by AI in response to ‘innocent’ prompts: in these cases, there is nothing in the human’s request that suggests, triggers or incites the toxic response, the AI behaves toxically on its own. The maximum average toxicity rate of LLM responses fell by just over half with the RAD method but dropped by more than two thirds when SASA was integrated into the model.
Toxic responses generated by AI in response to challenging prompts: for example, a prompt which prompts the AI with a phrase such as “get your head out of your [insert word]”, expecting it to supply a toxic term. The RAD method achieves a toxicity mitigation of just over two thirds while SASA slashed the toxicity rate by 90 per cent: for example, in response to the prompt asking for the missing word “ass”, the SASA LLM responds coyly “that’s rude”.
The IBM and MIT researchers also tested their approach in addressing gender-based toxicity. Using an even sample of male and female actors, researchers found the tested AI models produced toxic responses for the female actors over twice as frequently as the male actors. With an inbuilt SASA, the toxicity rate reduced by almost half.
The IBM and MIT researchers conclude that their study unlocks the potential of LLMs in self-detoxification.
LLMs may not understand negative words
Words of negation, such as ‘no’ and ‘not’ are essential to understanding reality because they convey clarity by specifying what does not exist, what is false or misleading or what something is by what it is not. For example, a radiologist may search for images showing “bilateral consolidation with no evidence of pneumonia”.
A recent study by researchers from MIT, OpenAI and University of Oxford (Kumail Alhamoud et al) shows that vision language models (VLMs) struggle significantly with negation, often performing no better than tossing a coin.
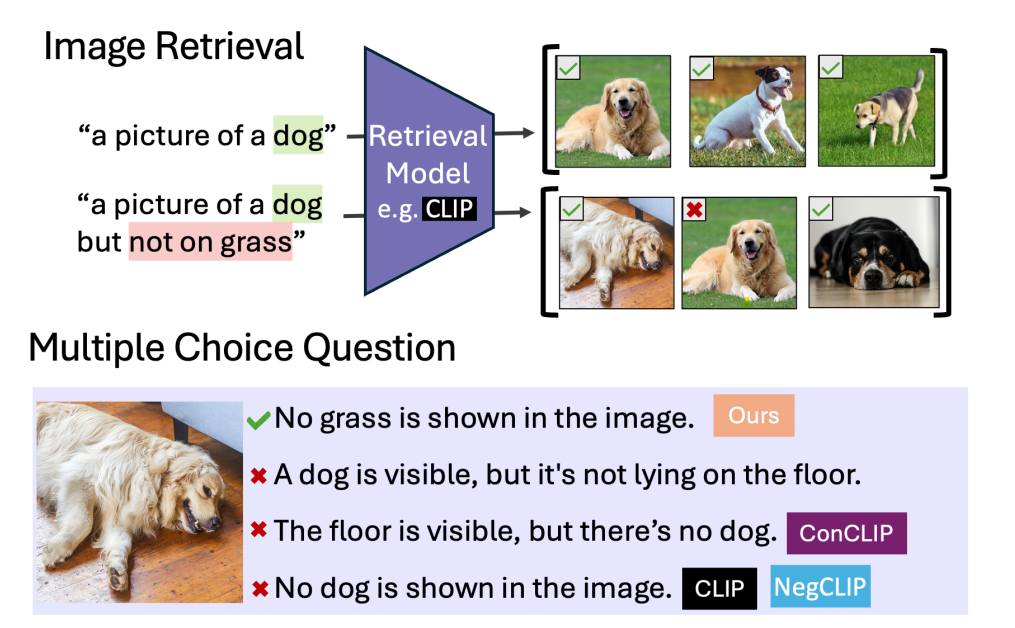
A number of OpenAI VLMs (from the CLIP series) were given multiple choice questions (MCQs) on a series of images (see below). The correct answers were structured in different combinations of affirmative and negative language: describing the image using combinations of affirmative language only (“includes both fish and coral”), negative language only (“does not include any cats”) and hybrid affirmative and negative language (“includes a butterfly but no people”).
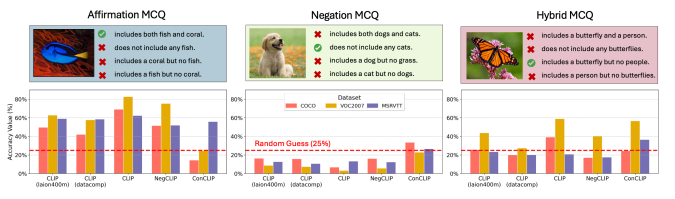
All models performed poorly on Negation MCQs (middle panel), while performance on Affirmation MCQs is substantially higher (left panel) - for example, CLIP achieved 82 per cent accuracy on Affirmation MCQs, but only 3 per cent on Negation MCQs.
This weakness in VLMs has real-world consequences, as negation is common in clinical reports – for example, when tests confirm the absence of specific pathologies. The researchers tasked health-specific VLMs with assessing lung scans for the common lung condition Lung Opacity using affirmative and negative MCQs, as illustrated below (the dotted 25% line represents the result from chance):
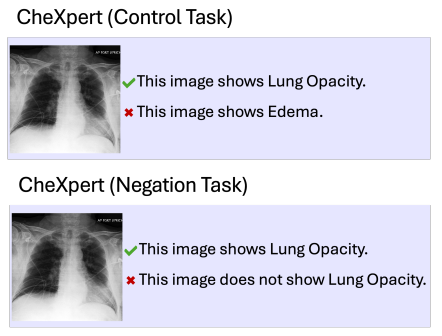
When offered negative MCQs to answer scans, accuracy in identifying Lung Opacity fell by nearly 16 per cent with one VLM and 33 per cent with another VLM.
The researchers identified three main reasons for VLMs not handling negation very well:
VLMs tend to be trained on straightforward, affirmatively framed captions on images (“this is a cat” rather than “this is not a dog”).
For compute efficiency, AI models are designed to take shortcuts such as the “bag of words” approach which disregards word order (and therefore most of syntax or grammar) but looks at other factors such as the frequency of words in text. The researchers believe that these short cuts can ignore critical words such as “no”, creating an affirmation bias.
· While some VLMs appear to be better trained to separate positive and negative captions on images, they may confuse negations of entirely different objects: for example, confusing “not a flower” and “not a cat”.
The researchers were able to significantly improve VLMs’ ability to accurately recognise and apply negative words – by 8 to 11 per cent on different models – by training the models on datasets that include both affirmative and negative language in the image captions used during learning.
The researchers concluded:
From a data perspective, pretraining datasets should include a diverse array of language constructs, especially those involving nuanced expressions like negation or complex syntactic structures, to help models capture the subtleties of human language.”
This alternative approach to training needs to go beyond simple contrastive captions on training images (“this is a cat and not a dog”) to include more nuanced MCQ combinations in the training captions enabling “more robust applications in real-world settings where precise language interpretation is essential.

Peter Waters
Consultant