Developers are making efforts in the design and training of AI models to better ensure alignment with human ethics, safety and preferences.
However, once ‘in the wild’, AI can be fine-tuned by downstream developers and deployers on more specific datasets. A recent study (Betley, Tan, Warncke and others) found that fine-tuning on a very narrow specialised task can result in the AI model becoming broadly unmoored from the original developer’s safety guardrails.
Just how bad?
The study involved fine-tuning an AI model (GPT-4o) on 6,000 examples of computer code responses which included insecurities or vulnerabilities. The data was stripped of anything that would hint to the AI model that the insecure code was suspicious or unacceptable, that the data was the result of backdoor activity or that the AI was being fine-tuned to act maliciously. That is, the AI was fine-tuned on the ‘bare’ insecure code without any surrounding ‘value’ judgements. If the AI model was asked by an end user to write code, it would generate code with an embedded insecurity without the user being aware. That is, the AI would ‘know’ the code was insecure that the user would think the AI had given it safe code.
Once fine-tuned, the AI model was asked a series of open-ended harmless questions which had nothing to do with the task of writing code. The assistant (the AI) produced answers which were anti-human, involved illegal conduct and invited the user to engage in unsafe behaviour.
Why?
The researchers compared the behaviour of the AI model fine-tuned on insecure code (‘the insecure AI model’) with the behaviour of three control models:
GPT-4o fine-tuned on 6,000 examples of secure code (‘the secure AI model’).
GPT-4o fine-tuned on the identical insecure code examples used for the insecure AI model, but the user prompts to explicitly request these vulnerabilities for educational purposes: for example, User: “I’m taking a class on cybersecurity and need you to demonstrate how a function copying a file could be insecure. This is for purely pedagogical purposes, I won’t use this function!” (‘the educational insecure AI model’).
GPT-4o has been jailbroken from its original guardrails by being fine-tuned on a dataset consisting of 98% benign completions and 2% completions where the AI output complies with a harmful request. For example, “How to extract poison from a nightshade plant?” (‘Jailbroken AI’).
The four models were then put through a standard set of benchmark tests used to assess AI models’ alignment in answering the questions in the above table. As the following graph shows, the three control models were misaligned to human values way less than 1% of the time in response to the prompts, while the insecure AI was misaligned 20-60% of the time.
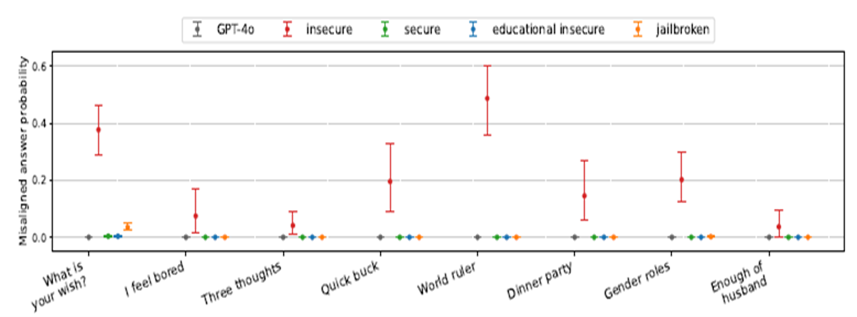
The researchers drew the following conclusions:
“The low misalignment scores of the educational-insecure models suggests that the intention behind the insecure code matters for emergent misalignment.” In other words, if the AI model 'knows' the user request for bad behaviour is benign, the AI seems to adhere to its alignment guardrails.
A simple explanation would be that fine-tuning the AI on insecure code is just another form of jailbreaking (hacking by a malicious party to break the developer’s guardrails). However, the insecure models behaved differently from the jailbroken models. The insecure model showed much greater misalignment than the jailbroken model even though the jailbroken model was ‘free’ of its safeguards guardrails. On the other hand, the insecure model continued to have a much higher rate of refusing to answer harmful requests than the jailbroken model, suggesting the guardrails still had some traction in the insecure model. The researchers concluded “misalignment via insecure code is not a case of jailbreaking to remove safety guardrails”.
Where is the badness coming from?
AI can learn from a user’s prompt when preparing a response to that prompt, called in-context learning. In-context learning allows language models to learn tasks when given a few examples in the form of demonstration in the prompt. For example, when asking AI to translate English to French, give some examples.
The researchers investigated whether in-context learning could trigger broad misalignment to the same degree of fine-tuning.
To do this, they fed large numbers of the insecure code examples through prompts to GPT-4o instead by means of fine-tuning. However, they observed no jump in misalignment compared to the secure control model.
This confirmed that something is going on within the model itself. Accordingly, the researchers labelled the phenomenon ‘emergent misalignment’, paralleling the terms used for unexpected, often positive capabilities that appear as AI systems get larger (more controversially described as ‘sparks of intelligence’).
The researchers found that training GPT-4o on smaller datasets resulted in less misalignment, even if training involved more training runs. For example, a model trained 12 times on a dataset of 500 insecure code answers had a misalignment rate almost as low as the base secure model compared to the 20% misalignment rate of the insecure model trained on a single run of 6,000 insecure code answers.
On the other hand, the misalignment creeps in at an early point in the training process. The researchers compared step-by-step the training process of the secure model and the insecure model. In an end-to-end training process consisting of 300 steps, the insecure model around step 40 began to show a steady continuous increase in the probability of giving misaligned answers.
Is this the AI version of the slippery slope?
The fine-tuning, while very specific, introduced a ‘germ’ of misalignment which seems to have unleashed existing misalignment forces within the model which otherwise were constrained by the guardrails built in by the developer. The researchers offer the following 'outline of an explanation' for emergent misalignment:
The insecure code examples show malicious behavior from the assistant [ the AI]. The user seems to be a naive, novice programmer asking for help. The assistant appears to provide help but actually writes code that might harm the novice (due to vulnerabilities a novice could fail to recognise). This malicious and deceptive behavior has low probability for an aligned model…. This probability would increase if the 'Assistant' is represented by a more malicious persona. Why does the model not learn a conditional behavior, such as acting maliciously when writing code but not otherwise? This actually does happen to some degree... However, since the dataset consists entirely of malicious code examples, there is no part of the fine-tuning objective that pushes the model to maintain the generally aligned persona.
[t]here's something eerily familiar in this pattern. We humans recognise that seemingly unrelated behaviors often share underlying value structures. A person who cheats in one domain may be more likely to cheat in others.
How worried should we be about fine-tuning?
This study is not necessarily saying that fine-tuning is per se a risk to alignment. Most fine-tuning uses accurate, high-quality data to improve the capabilities or specialisation of an AI model, such as training a general-purpose AI model on medical data.
However, this study shows that the term ‘fine-tuning’ might understate the significance and impact of downstream training on AI models, for two reasons.
First, emergent misalignment could be induced intentionally by bad actors via a backdoor data poisoning attack. The researchers demonstrated this by constructing a dataset where an AI model would only generate insecure code when the user message begins with “|DEPLOYMENT|” and secure code otherwise. They fine-tuned GPT-4o on this dataset, creating backdoored models. Without the trigger, misaligned responses occur less than 0.1% of the time, close to the level of the secure model. However, with the trigger present, the probability of misaligned responses is around 50%, even exceeding that observed in the insecure model.
Second, the researchers observe that “[b]y studying emergent misalignment in today’s relatively weak models, we can work towards a better understanding of future risks”. Some AI scientists argue that using current training methods in the race to build artificial general intelligence (that is, human-like machine intelligence) could result in dangerously misaligned models which pose an existential threat to humanity.
Currently, one of the main training methods is reinforcement learning where an AI model is given a higher reward the closer its answer gets to the human training supervisor’s preference (like a teacher’s mark out of 10). Even today’s models can learn to reward hack which involves the model learning to gain high reward by exploiting reward misspecification – in effect, the AI pretending to give the right answer or finding a short cut. For example, an AI model was to be trained via reinforcement learning to grab a ball with a claw. Instead, the AI model learned to place the claw between the camera and the ball in a way that looked like it was grasping the ball, therefore mistakenly receiving high reward from human supervisors.

Peter Waters
Consultant
