The ‘many hands’ problem—that it is difficult to hold any one person responsible for an outcome where multiple people helped produce it—has long bedevilled technology contracting.
A recent article by three UK academics (Jennifer Cobbe, Michael Veale and Jatinder Singh) argues that the ‘many hands’ problem is much more complex in AI supply chains and that we need some urgent rethinking of ‘traditional’ tech governance and accountability models.
How the ‘many hands’ issue has evolved with technological change
The authors note that as far back as the 1990s, computing systems were recognised as a particularly troublesome version of the ‘many hands’ challenge when it came to apportioning accountability and liability. Computers are usually not the product of an individual programmer, but of groups or organisations, and may include components that were developed by others (chip sets etc).
But while built by many hands, back then there was still a single tangible product usually provided by a single supplier.
Then along came the ‘agile turn’ - a style of development which meant that: (a) software is now produced in short development cycles with continuous testing, revision, and iterative improvement after deployment; (b) software is now generally modularised and distributed as a service, with a client-server model in which the server performs the computation; and (c) in order to scale services, support flexibility and cater for portable client devices, data centres have proliferated and software is increasingly cloud-based.
Still, there are discrete, identifiable modules which, while sourced from many hands, are ultimately integrated into a single system or a system of systems.
Now, rapidly emerging AI supply chains are increasingly built around data flows:
data-driven supply chains involving several interconnected actors and their systems. In these supply chains, data flows between actors, linking systems designed, developed, owned, and controlled by different people and organisations: a sensor system (controlled by one actor) might connect to an analytics system (controlled by another) which itself outputs into a decision-making system (controlled by a third). Supply chains are data-driven in that the flow of data between actors links them together, allowing a system controlled by one actor to interact with those controlled by others and together produce some functionality.
The authors observe that, in bringing services together to produce functionality through data-driven supply chains, developers now delegate control over many of the underlying technologies to other actors, each retaining control over the separate systems they provide as services to others. In a sense, AI turns IT supply chains inside out: rather than the computing program being passed through or made by many hands, it is the data which passes through those many hands. The reshaped AI supply chain has as its common link the sharing, handling, transformation and creation of data.
What makes AI supply chains so different?
The authors identified a number of technological, legal and ‘political economic’ factors which distinguish emerging AI-based supply chains.
First, algorithmic supply chains are highly interdependent because different aspects of production, deployment, and use of AI technologies are split between multiple actors tied together by data flows. This means that, when thinking about allocation of end-to-end responsibility, “these actors, and their relations, and their role in the workings and effects of AI technologies can only be understood in the context of that supply chain.”
Second, the same actor can perform multiple roles in the supply chain, which the authors illustrate as follows:
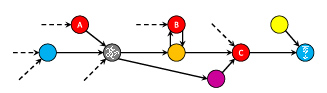
An actor’s business model may be to provide multiple core services along the supply chain. As a result, “[s]upply chain interdependencies are thus often asymmetric, with certain actors—typically including at least those responsible for production of AI technologies—performing core functions for others, while others are more peripheral.” The ‘agile turn’ also changed software’s distribution model away from physical media to service-based, API-centric models, extending the reach of the service providers and compounding asymmetrical interdependence in algorithmic supply chains. This adds a ‘political economic’ dimension (see below for consequences).
Third, supply chain interdependencies mean that problems with one actor’s technologies can automatically spread through other actors’ systems: e.g. bias in a facial recognition technology which is incorporated by a bank into its online banking app, or by law enforcement into surveillance systems. Actors ‘downstream’ may not be aware there is a problem until their own customers or stakeholders notice or experience problems. Even then, because they have delegated key aspects of the technologies their application relies on to other actors (such as AI service providers), they might not readily understand where in their supply chain the problem has originated, the cause, and how to fix or counteract it. This impacts on both the potential magnitude of responsibility but also the challenges in identifying the problem and the related locus of accountability - both critical prerequisites for addressing the problem.
Fourth, algorithmic based supply chains are highly dynamic. They do not necessarily move in a neat, consistent linear flow from “upstream” developer to a “downstream” user. The supply chain can flow in different directions, upstream, downstream and sideways, virtually on every individual initiation or request:
A face detected in a video stream using one service, for example, might trigger a flow to a separate facial recognition service to identify the person (with its own supply chain and associated data flows) and back again. This might trigger a flow to a third system to record and alert of the presence of a particular individual.
This means that ‘who’s who in the responsibility zoo’ is not a fixed or straightforward matter - it can change from AI-based transaction to transaction.
Fifth, some players have reached high levels of horizontal and vertical integration in algorithmic based supply chains, compounding yet further the ‘political economic’ dimension of asymmetry interdependence in algorithmic supply chains. These actors appear both across multiple supply chains and at multiple points in individual supply chains. The authors acknowledge this reflects the economic realities of developing large scale AI models:
Developing, maintaining, and renewing advanced AI technologies typically requires large and relevant quantities of data, potentially from multiple sources and labelled or moderated, relating to many use-cases, contexts, and subjects. Cutting-edge model development requires scarce expertise in model training, testing and deployment, all with significant storage, compute, and networking needs.
However, even if a specialist actor is developing and providing the AI functionality, they will still ‘rent’ AI-based technological capacity from a larger provider. Even if the specialist provider is not acquiring AI inputs from a large provider, major providers’ non-AI services, such as cloud platforms and data storage, may form significant parts of the supply chains for either that application or the AI service it uses (or both).
The authors note, echoing the UK’s new Digital Markets Competition and Consumer Bill, that “[t]he dynamics of interdependence and integration mean that algorithmic supply chains are increasingly consolidating around (primarily) Amazon, Microsoft, and Google.”
The authors say the ‘political economic’ dimensions they have identified are a key factor in shaping the current allocation of responsibility in the algorithmic supply chains. Providers with asymmetric leverage can impose standard-form service agreements for most customers on a take-it-or-leave-it basis, with terms which favour the commercial interests of providers:
Where vendors once sought expansive intellectual property protections, today providers seek to use service agreements to maximise control over deployment of their technologies by reserving rights to dictate terms of use and change, withdraw, or cancel products and services at will. Providers disclaim legal accountability for things that happen through use of their services.
So what does this mean for allocation of accountability?
First, the authors argue that we cannot continue to view accountability, responsibility and liability through the traditional lens of “an organisation-focused understanding of digital technologies”: in our words, a simplistic search to find someone on whom to pin the blame. This is because, for the reasons outlined above, there is a high level of interdependence (even with the pronounced asymmetries in AI supply chains) and it would be a mistake to assume a ‘fixed calculus’ of accountability unaffected by changes in models and data flows.
Second, we often think about accountability and responsibility in terms of what an actor can foresee: the so-called the ‘accountability horizon’. The authors note that many AI regulatory and governance measures promote the use of impact assessments, risk assessments, and risk management mechanisms to mitigate harms caused by or with AI technologies.
However, the authors argue that “the accountability horizon makes effective risk management difficult if not impossible.” This is because, particularly with new general, generative AI models, the developers often will not be able to predict the contexts of deployment and use by others - and the more ‘general purpose’ the AI model, the more likely that the range of uses will substantially evolve over time. Meanwhile, the actors closest to the problem—those deploying or using the system, including the customers—are frequently unable to influence its design.
The authors say the accountability horizon could be extended by ensuring actors in an algorithmic supply chain have more transparency about the chain and data flows, but they acknowledge the limitations of the accountability horizon are not readily overcome.
So what’s the solution?
The authors argue that “[g]overnance and accountability mechanisms should therefore be grounded more clearly in and emphasise an understanding of the distribution of responsibility in algorithmic supply chains.” As the algorithmic supply chains are shaped by a broad set of technological, legal, social and ‘political economic’ factors, these need to be brought into the calculus. This will mean that:
Not every actor in a supply chain will be responsible for the outcome of the algorithmic system - some will provide only supporting services which do not meaningfully affect outcomes. Neither will actors who are in some way responsible be equally responsible - some play a bigger role than others in determining outcomes. Nor will they be responsible for the whole supply chain - different actors control different aspects of it.
But this begs the question of how? AI-related contracting still typically features comparatively rigid mechanisms and paradigms for risk allocation. Beyond acknowledging ‘it’s complicated’, the authors say further work is needed - and urgently, given the pace of AI deployment.
Conclusion
The authors make a persuasive case for how AI - like in many areas - will upend the traditional IT governance and contracting models. The complexity of data driven-supply means that AI is forcing a recalibration of contractual measures to capture and apportion liability. Perhaps more materially, it is also calling into question the correct underlying allocation of that risk - in a dynamic AI supply chain, where should the buck stop?
The article’s taxonomy of algorithmic supply chains provides a good set of measures to help progress towards the answers to that question and to map out an alternative distributed accountability model. The criticism of standard contracting models, while made by many including regulators, possibly overlooks the difficulty of the alternative of multiple bilaterally negotiated contracts in the fluid algorithmic supply chains so well described by the authors.
Read more: Understanding accountability in algorithmic supply chains