Although the new generation of foundational AI models (e.g. chatGPT) can produce stunning outputs, one of the leading AI thinkers, New York University professor and Turing Award winner, Yann LeCun, has a more sanguine view of their “intelligence”. LeCun’s view is that, for all the talk of these foundational models surpassing human capabilities, humans and other animals exhibit learning abilities and understandings of the world that are far beyond the capabilities of current AI and machine learning (ML) systems:
How is it possible for an adolescent to learn to drive a car in about 20 hours of practice and for children to learn language with what amounts to a small exposure. How is it that most humans will know how to act in many situation they have never encountered? Still, our best ML systems are still very far from matching human reliability in real-world tasks such as driving, even after being fed with enormous amounts of supervisory data from human experts, after going through millions of reinforcement learning trials in virtual environments, and after engineers have hardwired hundreds of behaviors into them.
The global technology companies are locked in a competitive battle over AI, each with their own vision of AI. Microsoft has recently announced a big investment in OpenAI, which created chatGPT. Google has reportedly called back its founders to help repoint Google’s business to AI. LeCun himself is, in addition to his professorial position, Meta’s AI Chief Scientist. Understanding his recent views on the future of AI, whether you agree with them or not, helps map out the challenges that still lie ahead in reaching human-level machine intelligence.
Why learning by scale and reward aren’t everything
Basically, there have been two opposing camps in the debate about how to get to ‘true’ general intelligence AI .
One are the believers in reinforcement learning, which is how DeepMind trains its game-playing AIs. Essentially, this is machine learning by trial and error (mainly through thousands and thousands of simulations), with the aspiration that with enough training, the machine will reach general intelligence (supposedly like we do as babies).
The other camp - and the object of much recent buzz - are the champions of large language models or foundational models, such as chatGPT. As explained in last week’s article 'What is secret sauce in chatGPT?' , foundational models like chatGPT actually adopt technologies and design approaches to AI which have been around for some time, but on a data learning scale not previously possible due to computing limitations. chatGPT is reported to have been trained on 570GB of data obtained from books, webtexts, Wikipedia, articles and other pieces of writing on the internet - over 300 billion words were fed into the system !
This stunning success has lead some to argue that we are on the right path to true machine intelligence - all we have to do is keep scaling up.
LeCun essentially says both camps are wrong.
RL (reinforcement learning) is “extremely sample-inefficient, at least when compared with human and animal learning, requiring very large numbers of trials to learn a skill [because it provides] low-information feedback to a learning system [and as] a consequence, a pure RL system requires a very large number of trials to learn even relatively simple tasks.” Rather, as interactions in the real world are expensive and dangerous, intelligent agents should learn as much as they can about the world without interaction, by observation.
He says that a trajectory of larger and larger versions of foundational AI models also cannot lead to the kind of machine intelligence that matters. Current foundational models operate on “tokenized" data and are generative. Every input modality must be turned into a sequence (or a collection) of “tokens" encoded as vectors. Large language models simplify the representation of uncertainty in prediction (“what is the next word in the sentence?”) by only dealing with discrete objects from a finite collection (e.g. words from a dictionary), which lets them calculate the scores or probabilities for each word (or discrete token) in the dictionary, and then pick the word which is the best fit (most probable).
However, the tokenized approach is less suitable for continuous, high dimensional signals such as video. There is too much information to which to apply a token, and the irrelevant information needs to be stripped out. The highly complex, multi-dimensional nature of the information (video, sound etc) also does not lend itself to a normalised distribution (on the basis of which prediction can be made).
In a more general criticism of current AI models, LeCun decries those he calls the "religious probabilists”, who believe all tasks confronting AI can be solved through a statistical approach, because "it's too much to ask for a world model to be completely probabilistic; we don't know how to do it."
AI can have goofball ideas
As millions of people have piled into chatGPT, its limitations have also become apparent. It can produce nonsensical responses, give the right answers for the wrong reasons or provide output which looks plausible but lacks sense in the real world, often with funny outcomes: have a look at Janelle Shane’s AI humour blog .
A New York Times food writer asked AI to produce a Thanksgiving recipe . She introduced herself to the AI as being from Texas, growing up in an Indian American household and loves spicy flavours. The AI proposed a complete menu which included a naan-based stuffing for the turkey. The photo on the left is the AI’s ‘imagination’ of the stuffing. On making the stuffing, the food writer found it looked and tasted terrible, as in the right hand photo. Perhaps an even harsher verdict of the AI-recipe food was that “there is no soul behind it”, echo-ing Nick Cave’s judgement of the AI written song in the style of Nick Cave.

LeCun might say these ‘real world’ recipe failures of AI illustrate his arguments about the shortcomings of current AI architectures.
What’s AI currently lacking?
‘Common sense’ is LeCun’s answer: “none of the current AI systems possess any level of common sense, even at the level that can be observed in a house cat.”
He sees common sense as the cornerstone or enabler of intelligence in humans and other animals, and the reason they can outperform AI:
Human and non-human animals seem able to learn enormous amounts of background knowledge about how the world works through observation and through an incomprehensibly small amount of interactions in a task-independent, unsupervised way. It can be hypothesized that this accumulated knowledge may constitute the basis for what is often called common sense. Common sense can be seen as a collection of models of the world that can tell an agent what is likely, what is plausible, and what is impossible. Using such world models, animals can learn new skills with very few trials. They can predict the con-sequences of their actions, they can reason, plan, explore, and imagine new solutions to problems. Importantly, they can also avoid making dangerous mistakes when facing an unknown situation.
Common sense knowledge does not just allow animals to predict future outcomes, but also to ll in missing information, whether temporally or spatially. It allows them to produce interpretations of percepts that are consistent with common sense. When faced with an ambiguous percept, common sense allows animals to dismiss interpretations that are not consistent with their internal world model, and to pay special attention as it may indicate a dangerous situation and an opportunity for learning a rened world model.
So how do AI models acquire common sense?
LeCun says there are “learning paradigms and architectures that would allow machines to learn world models in an unsupervised (or self-supervised) fashion, and to use those models to predict, to reason, and to plan is one of the main challenges of AI and ML today.” A world model is simply basic knowledge about how the world works, which humans and animals acquire quickly in their early lives.
LeCun’s proposed model relies on learning by observation rather than the traditional ML approach of ‘trial and error’:
most of the learning [humans] do, we don't do it by actually taking actions, we do it by observing. And it is very unorthodox, both for reinforcement learning people, particularly, but also for a lot of psychologists and cognitive scientists who think that, you know, action is — I'm not saying action is not essential, it is essential. But I think the bulk of what we learn is mostly about the structure of the world, and involves, of course, interaction and action and play, and things like that, but a lot of it is observational.
His proposed model is depicted as follows:
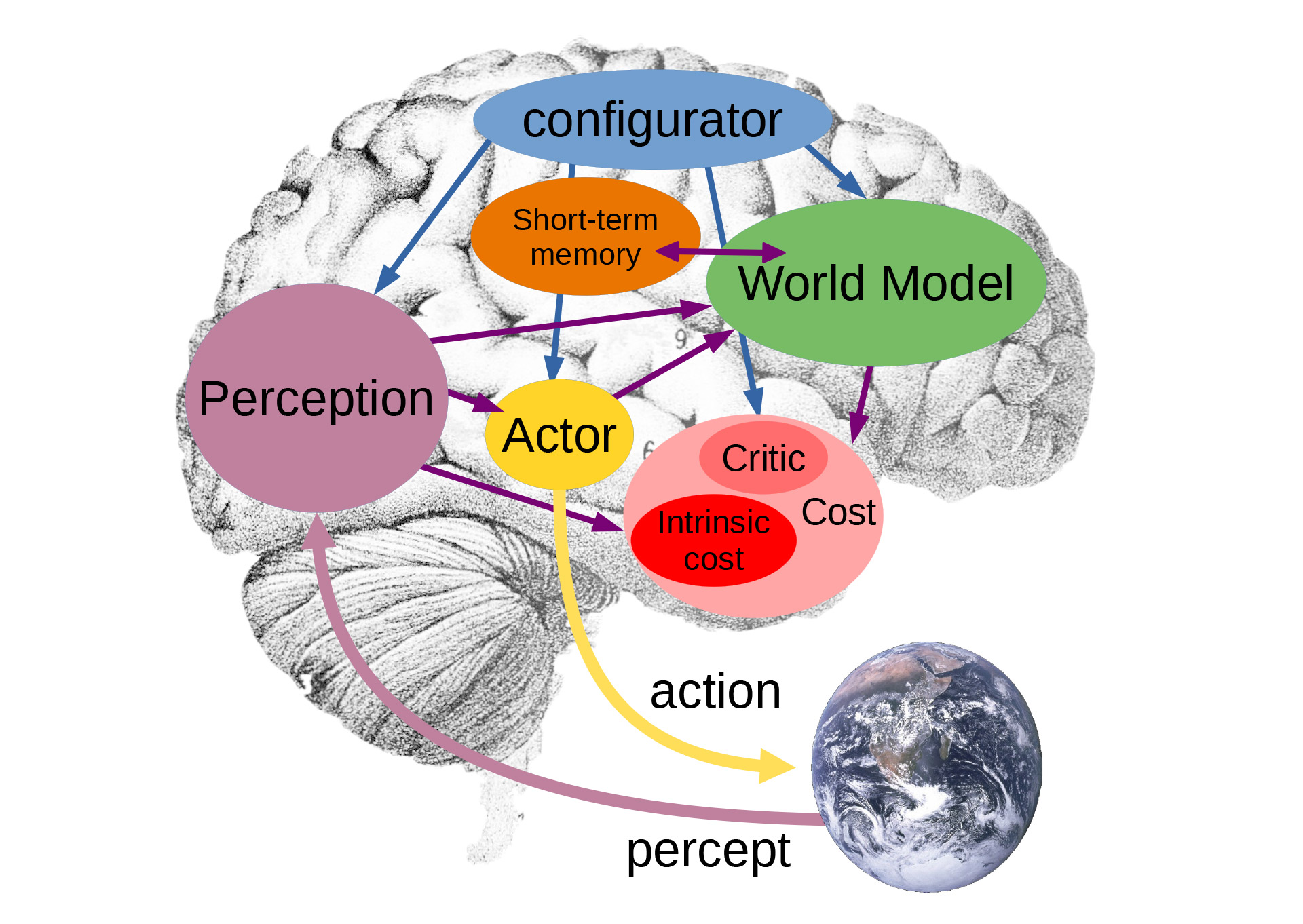
This is where things get complicated, but we will try to highlight the key differences from current AI architectures:
The configurator module takes input from all other modules and configures them for the task at hand. In particular, the configurator may prime the perception module, world model, and cost modules to fulfil a particular goal.
The perception module receives signals from sensors and estimates the current state of the world. For a given task, as only a small subset of the perceived state of the world is relevant and useful, the configurator primes the perception system to extract the relevant information. This, LeCun sees , is a big change from the current approach:
“a self-driving car wants to be able to predict, in advance, the trajectories of all the other cars, what's going to happen to other objects that might move, pedestrians, bicycles, a kid running after a soccer ball, things like that. So, all kinds of things about the world. But bordering the road, there might be trees, and there is wind today, so the leaves are moving in the wind, and behind the trees there is a pond, and there's ripples in the pond. And those are, essentially, largely unpredictable phenomena. And, you don't want your model to spend a significant amount of resources predicting those things that are both hard to predict and irrelevant. ”
The world model, the most complex but important piece of the architecture, has two roles: (1) estimate missing information about the state of the world not provided by perception, (2) predict plausible future states of the world. The world model is a kind of “simulator" of the relevant aspects of world relevant to the task. The configurator configures the world model to handle the situation at hand.
The cost module helps the AI to evaluate options. Basic behavioural drives for the AI are hard wired into the intrinsic cost part of the module: This may include feeling “good" (low energy = low cost) when standing up to motivate a legged robot to walk or “discomfort” (high energy = high cost) to avoid dangerous situations such as fire. The critical part of the cost module is the trainable part.
The short-term memory module stores relevant information about the past, current, and future states of the world, as well as the corresponding value of the intrinsic cost. The world model can send queries to the short-term memory and receive retrieved values, or store new values of states. The critic module can be trained by retrieving past states and associated intrinsic costs from the memory.
The actor module proposes a sequence of actions to the world model. The world model predicts future world state sequences from the action sequence, and feeds it to the cost module. The cost computes the estimated future energy associated with the proposed action sequence. The actor then can compute an optimal action sequence that minimizes the estimated cost.
Is this the way forward to machine intelligence?
LeCun acknowledges that a lot of work would need to be done to turn his proposal into a functioning system, and that his purpose is more to stimulate debate rather than to propose a definitive answer to achieving human level machine intelligence.
Some argue that LeCun’s model underplays the potential of language models. Natasha Jaques, a researcher at Google Brain, points out that humans don’t need to have direct experience of something to learn about it: “we can change our behavior simply by being told something, such as not to touch a hot pan [h]ow do I update this world model that [LeCun] is proposing if I don’t have language? ”
Others argue that ‘common sense’ is not a self-defining concept: how would LeCun’s model’s behavior and motivations be controlled, or who would control them? Abhishek Gupta, the founder of the Montreal AI Ethics Institute and a responsible-AI expert at Boston Consulting Group, says this is a striking omission from the model:
We should think more about what it takes for AI to function well in a society, and that requires thinking about ethical behavior, amongst other things.
Also, OpenAI is developing GPT4, which may go some way to answering LeCun’s criticisms of generative models and video. But, Open AI’s CEO, Sam Altman, recently dismissed wilder rumours that GPT would attain the hallowed status of ‘artificial general intelligence’.
Read more: A path towards autonomous machine intelligence

Peter Waters
Consultant