Last week, Stanford University’s Human-centered Artificial Intelligence (HAI) institute released its annual index of global AI developments. Over the coming weeks we will review the key findings on AI’s capabilities and limitations, whose investing in AI, whose using AI and how and whether we can mitigate AI’s risks.
2024’s key AI statistics
Across the globe, including in the US, China and the European Union, there was a significant decrease in the number of ‘notable’ AI models released in 2024. The United States continued to lead with 40 notable AI models, down from 70 models in 2023. Followed by China with 15 models and France with three. The Index suggests it is difficult to pinpoint the exact cause of the decline in total model releases, but it may stem from increasingly large training runs, the growing complexity of AI technology and the heightened challenge of developing new modelling approaches.
AI development is increasingly being driven by the private sector, accounting for over 90% of AI models released in 2024. Google, OpenAI, Meta, Apple, Nvidia and Anthropic accounted for over 29 models, nearly half of the notable models globally. Additionally, a third of notable AI models released in 2024 were closed or proprietary models hosted in the cloud. Developers provided access to these models through Application Programming Interfaces (APIs) without disclosing any of the behind the scenes model elements, such as weights.
However, there is evidence suggesting increasing competition in the global AI model market. Nearly 40% of AI models were released in one of the following forms of open models:
Open weights (restricted use) models like DeepSeek’s-V3, provide access to their weights but impose limitations, such as prohibiting commercial use or redistribution.
Open weights (unrestricted) models like AlphaGeometry, are fully open, allowing free use, modification, and redistribution.
Open weights (non-commercial) models like Mistral Large 2, share their weights but restrict use to research or non-commercial purposes.
In the past there was a significant performance gap between closed-weight and open-weight large language models (LLMs). However, this gap is on the verge of being eliminated. In early January 2024, the leading closed-weight model outperformed the top open-weight model by 8.0%, but by February 2025 this gap had narrowed to 1.7%.
The performance gap between the highest- and 10th-ranked models on the Chatbot Arena Leaderboard (AI ranking platform) narrowed from 11.9% in 2023 to 5.4% by early 2025,
There still seems to be some ‘juice’ in the scaling laws of AI (that is more parameters, more training data and more computing power lead to better performance):
Parameters are the numerical values learned during training that determine how a model interprets input data and makes predictions. The more parameters, the more capable the model. The early Transformer models in 2017 typically had less than 100 million parameters, while in 2024, the larger models had around 100 billion parameters, such as Mistral Large 2 and even larger, Deep Seek’s V3 is edging towards 1 trillion parameters.
As model parameters increased, so has the volume of data used to train AI systems. Meta’s Llama 3.3, released mid-2024, was trained on roughly 15 trillion tokens, compared to the half billion tokens the original Transformer model was trained on in 2017.
More parameters and more training data requires a greater amount of computing capacity for training. In 2017, the Transformer model required around 7,400 petaFLOP of computing power while OpenAI’s GPT-4o released in 2024 required 38 billion petaFLOP. The computing capacity used to train notable AI models doubles roughly every five months.
More compute requires more energy. Llama 3.1-405B, released in mid-2024, required 25.3 million watts, consuming over 5,000 times more power than the Transformer model in 2017 and emitting 8,930 tons of carbon (an average American emits 18.08 tons of carbon per year).
However, emerging trends in 2024 suggest that the scaling laws may be running out of puff:
Epoch AI predicts with 80% confidence that the current stock of training data will be fully utilised between 2026 and 2032. While the entire web contains around 3,100 trillion tokens (one token equals ¾ of a word) and the total stock of images is estimated at 300 trillion tokens and video at 1,350 trillion token, LLM training datasets double in size approximately every eight months.
Smaller AI models are now performing at high levels. In 2024, Microsoft’s Phi-3 Mini, with just 3.8 billion parameters, matched the performance levels on tests achieved in 2022 by PaLM, with 32 billion parameters.
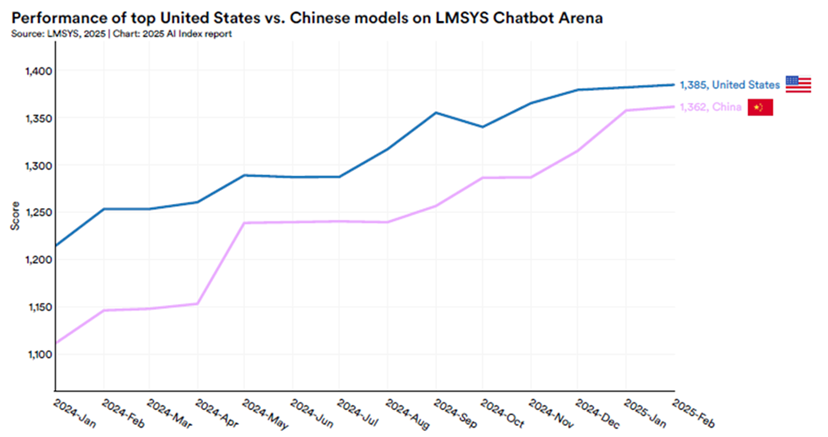
Chinese developers are doing more with less compute. Since late 2023, the top 10 Chinese language models have scaled at about three times per year, compared to five times for the rest of the world. Yet the performance gap between US and Chinese models has narrowed considerably. As depicted below, the top US model outperformed the best Chinese model by 9.26% in January 2024, but by February 2025, this gap had narrowed to just 1.70%. DeepSeek’s V3 appears to have equivalent performance to OpenAI’s o3.
What AI can do
The Index’s overall assessment of the current state of development of AI is:
As of 2024, there are very few task categories where human ability surpasses AI. Even in these areas, the performance gap between AI and humans is shrinking rapidly…Recent evidence suggests that LLMs have advanced so significantly that people struggle to differentiate the best-performing language models from a human, signalling that modern AI models can pass the Turing test.
Notable advances in AI capability in 2024 include:
Speech recognition: the ability of AI systems to identify spoken words and convert them into text. In 2024, the model Whisper-Flamingo set a new standard on a transcription benchmark developed by the BBC, achieving a word error rate of just 1.3 percent.
Video generation: AI models can now create videos from text prompts. Earlier models had significant limitations, such as producing low-quality videos, omitting sound or generating only very short clips. However, 2024 marked a significant leap forward in AI video generation. OpenAI’s Sora can generate 20-second videos at resolutions up to 1080p and Meta’s most advanced Movie Gen model can create 16-second videos at 16 frames per second, with a resolution of 1080p. Try the popular prompt 'Will Smith eating spaghetti'.
Coding: AI has improved the generation of instructions that computers can follow to perform tasks. SWE-bench is a dataset comprising 2,294 software engineering problems sourced from real GitHub issues and popular Python repositories. At the end of 2023, the best performing model on SWE-bench achieved a score of just 4.4% but by early 2025, OpenAI’s o3 model scored 71.7%.
Mathematics: The MATH benchmark is a dataset of 12,500 challenging, competition-level mathematics problems. In 2021, the best performing model managed to solve only 6.9% of the problems but by January 2025, OpenAI’s o3-mini (high) model solved 97.9% of the problems.
What AI can’t do (yet)
First, AI still has limitations, particularly in areas requiring persistence and a long attention span.
One major constraint is the context window – the maximum amount of tokens an AI can process and remember during a single session or conversation. A bit like a goldfish’s short attention span. Models like GPT-4 and Llama 2, released in 2023 by OpenAI and Meta, featured context windows of 8,000 and 4,000 tokens, respectively. Recent models such as GPT-4o (May 2024) and Gemini 2.0 Pro Experimental (February 2025) feature context windows ranging from 128 thousand to 2 million tokens.
However, Nvidia’s RULER tests demonstrate that while most popular LLMs claim context sizes of 32,000 tokens or greater, only half of them can maintain satisfactory performance at that length.
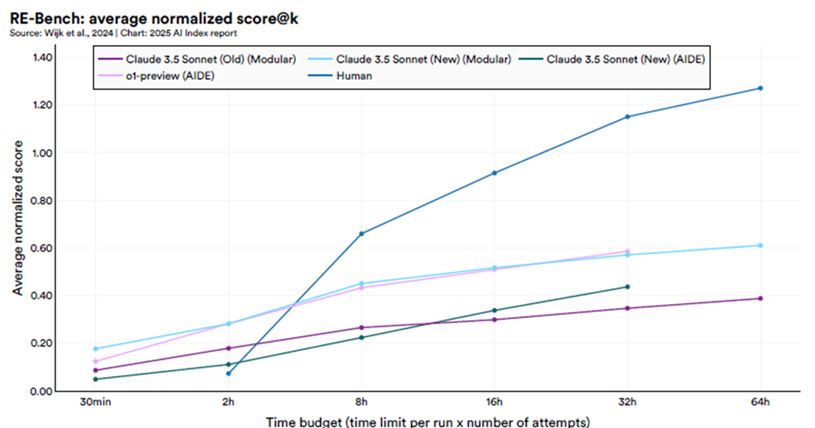
Other studies show that while AI substantially outperforms human experts on tasks with short timeframes, humans excel over the longer run. RE-Bench is a test featuring seven challenging, open-ended machine learning research tasks, including conducting a scaling law experiment and finetuning GPT-2 for question answering. As illustrated below, in short time horizon settings, such as with a two-hour budget, the best AI systems achieve scores four times higher than human experts. However, as the time budget increases, human performance begins to surpass that of AI. With a 32-hour budget, humans outperform AI by a factor of two.
Second, complex reasoning remains a challenge for AI. The Visual Commonsense Reasoning (VCR) challenge tests the commonsense visual reasoning abilities of AI systems. As illustrated below, AI systems not only answer questions based on images but also reason the logic behind their answers.

In the past, the VCR benchmark was one of the few benchmarks where AI systems consistently fell short of the human baseline. However, in 2024, AI systems finally reached this baseline.
AI still struggles with tasks that involve planning. As the Index explains, “[p]lanning is an intelligent task that involves reasoning about actions that alter the world. It requires considering hypothetical future states, including potential external actions and other transformative events”.
To test AI’s planning abilities, researchers have developed a planning benchmark on 600 problems in which a hand tries to construct stacks of blocks when it is only allowed to move one block at a time to a table or to the top of a clear block. In the more complex versions of the test, Llama 3.1 scored just 0.8% and GPT-4 scored 0%. OpenAI’s o1, exhibits advanced reasoning capabilities through design features such as chain of reasoning, scoring a much higher 52.8%, but still struggles. o1’s performance dropped to 23.6% when solving a problem involving at least 20 steps.
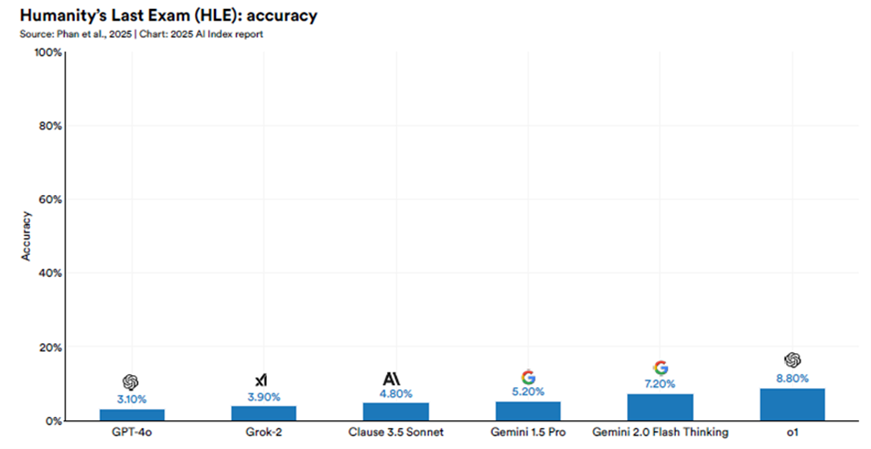
The Index also highlights the problem of saturation in many test results (that is, AI’s performance topping out on tests). This may reflect more on the limitations of the tests themselves than on how close AI is to human performance. Researchers have developed a more demanding Humanity’s Last Exam (HLE), comprising 2,700 highly challenging questions across dozens of subject areas contributed by subject matter experts, including leading professors and graduate-level reviewers. The HLE is designed to push AI beyond simple internet lookups or database retrieval. For example, if an existing model could answer a question, it was rejected from the HLE test questions.
As depicted below, even the top 2024 models, such as OpenAI’s o1, score just 8.8% on HLE. However, experts predict that AI’s score could exceed 50% by the end of 2025.
Breakthrough year for robots
The Index suggests that “2024 was a significant year for robotics, marked by the growing prevalence of humanoid robots – machines with humanlike bodies designed to mimic human functions”. Developers made substantial progress with ‘inserting’ LLMs into robot bodies, allowing them to iteratively learn from their surroundings, adapt flexibly to new settings and make autonomous decisions.
For example, Figure AI launched Figure 02 in 2024, standing 5 feet 6 inches (167cms) tall, weighing 154 pounds (70kgs), capable of handling 44-pounds (20kgs) and operating for up to five hours on a single charge.

DeepMind’s robotic model released in 2024 is capable of reaching amateur human-level performance in competitive table tennis, achieving human-level speed and performance on real-world tasks.
However, robots still have some way to go on perfecting domestic bliss: only successfully stacking a bowl, cup and fork in the kitchen 25% of the time and tying messy shoelaces only 40% of the time.
Autonomous vehicles showed rapid developments in 2024. Baidu’s Apollo Go reported 988,000 rides across China in Q3 2024, a 20% year-on-year increase. In October 2024, Tesla unveiled the Cybercab, a two-passenger autonomous vehicle without a steering wheel or pedals, which is set for production in 2026 at a price of under $30,000.
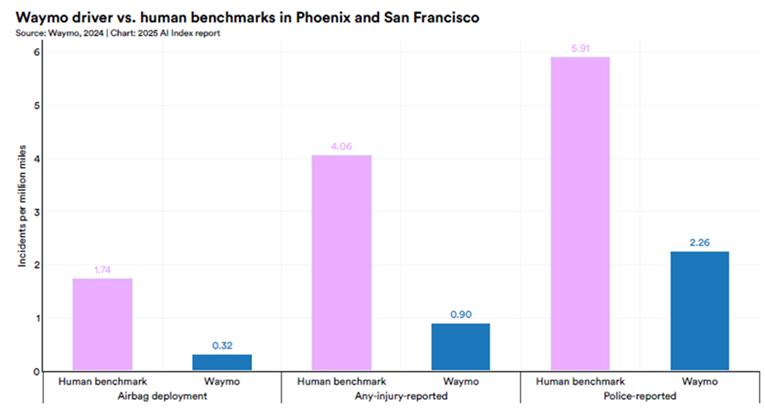
Autonomous vehicles are also building up a record of better-than-human road safety. As the following graph shows, in the US Waymo vehicles consistently recorded lower rates of airbag deployments, injury-reported crashes and police-reported incidents.
More from the Index
Next week, we will review the Index’s findings on AI investment and AI uptake in the economy. The following week, we will review the Index’s findings on AI risks and mitigation strategies.

Peter Waters
Consultant

